
Registrative vs Knowledge Graph
Het verschil tussen aanbodgedreven en vraaggedreven
In deze tutorial nemen we je mee in het idee van de Kadaster Knowledge Graph en tonen we het verschil tussen deze bron en de onderliggende data registraties.
SPARQL Tutorial
Doel van deze module
Na deze module, stap 3 van de tutorial, kun je aan je collega’s uitleggen:
- Wat het verschil is tussen de registratieve datasets en de Kadaster Knowledge Graph.
- Hoe er met historie moet worden omgegaan in de beschikbare linked data sets.
- Hoe de data lineage van de Knowledge Graph te benaderen is.
Introductie
Zoals je in de vorige tutorial hebt kunnen ervaren is er redelijk veel domeinkennis benodigd om te achterhalen hoe je de juiste query moet opstellen op de onderliggende basisregistraties. Zo hebben we onder andere:
- Rekening moeten houden met lege Z-coördinaten in de BAG.
- Rekening moeten houden met de historie van de objecten in de verschillende registraties en hoe deze te relateren zijn tussen objecten- en registraties.
- Verdubbeling van gegevens door het samenvoegen van verschillende objecten.
- Kennis moeten vergaren over datasets heen hoe deze tot elkaar gerelateerd zijn.
Om deze reden stellen wij sinds kort (zie ook de Integrale Gebruiksoplossing) een Knowledge Graph beschikbaar. Een uitgebreide uitleg over dit concept kun je ook vinden op onze architectuurpagina. In het kort maken we een view (“Representatie”) van de integrale data beschikbaar met daarin een verwijzing naar de originele brondata waaruit deze is opgebouwd.
Daarvoor maken we in deze tutorial gebruik van de Kadaster Knowledge Graph gebaseerd op Schema.org. Schema.org is een standaard geïntrodueerd door Google en behelst een manier van data omschrijving waarmee moderne zoekmachines goed aan de slag kunnen. Objecten, pagina’s en websites die met deze standaard zijn omschreven zijn dan ook over het algemeen goed vindbaar op het web. In onderstaand figuur wordt een voorbeeld van een datamodel in Schema.org gegeven.
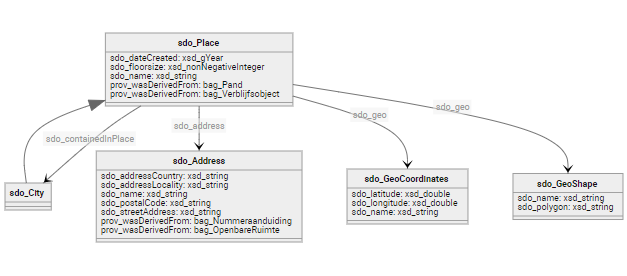
Datamodel en mapping
Uiteraard is er ook voor de Schema.Org knowledge graph een datamodel beschikbaar. Deze is visueel beschikbaar in Triply Insights. Zoals je in deze interface kunt zien is een plaats (sdo:Place) de centrale plek in dit model. Places zijn vervolgens weer onderverdeeld in wat vanuit de Integrale Gebruiksoplossing de belangrijkste objecten zijn in de basisregistraties, zoals Waterdelen, Wegdelen en Gebouwen.
Deze hierarchie in de verschillende places is ook terug te vinden in de named graphs van de dataset, waar op basis van verschillende invalshoeken de data in verschillende graven is opgedeeld.

Hoe we tot deze verschillende invalshoeken zijn gekomen is uitgebreid vastgelegd in deze documenterende pagina over de Knowledge Graph. Daar beschrijven we ook de hoe de nieuwe objecten (gebaseerd op schema.org) terug relateren naar de originele basisregistraties. Neem als voorbeeld de transformatie die wij toepassen om Places te genereren op basis van adressen, panden en gebouwen. Op basis van deze translatie creëren wij op basis van ieder Verblijfsobject in Nederland een place volgens de transformatie vastgelegd in deze documentatie.
Om een beter beeld te krijgen van zo’n Place, kijken we naar onderstaand resultaat:
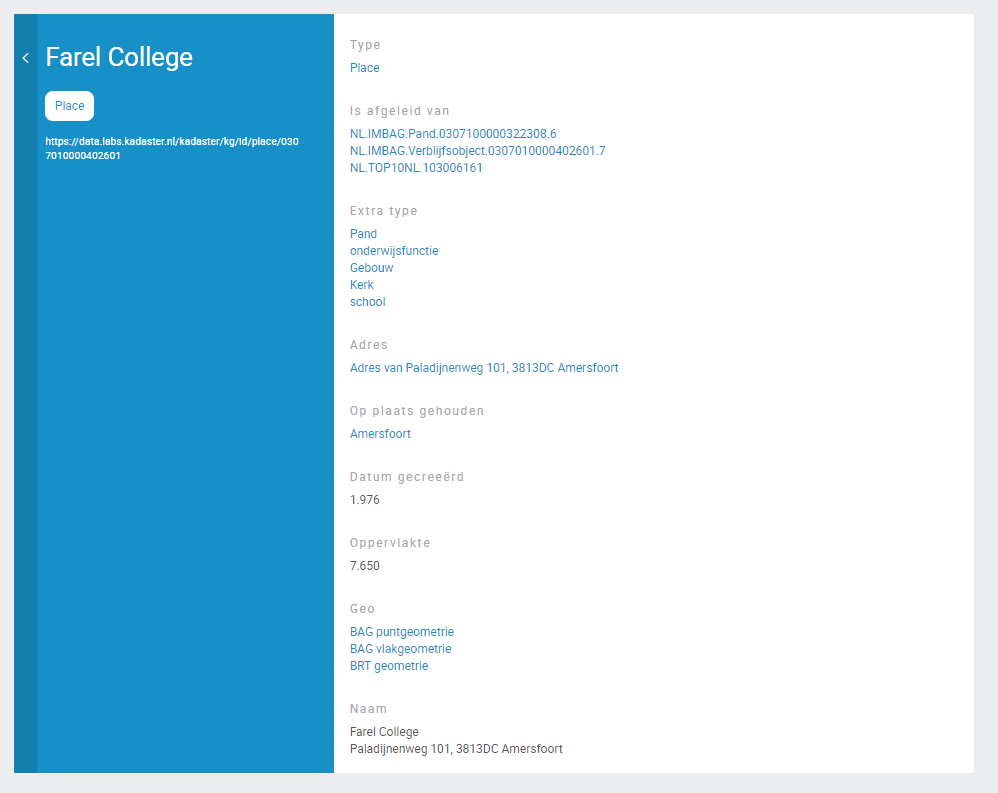
Een gevonden plaats heeft deshalve een aantal belangrijke kenmerken:
- De registraties uit de originele registraties waar deze van zijn afgeleid.
- Additionele types die verwijzen naar typeringen uit de bron, maar waar Schema.org niet expressief genoeg voor is.
- Verwijzingen naar geografische objecten in een gestandaardiseerd formaat.
- Attributen uit de objecten waarvan dit nieuwe object is opgebouwd.
Tip: Wil je weten hoe een place in jouw omgeving is opgenomen in de data? Kijk dan eens in onze Objectviewer en klik op het object waarnaar jij op zoek bent. Of zoek eens rechtstreeks in onze Elastic Search ingang naar het object van jouw interesse.
Gebruik van SPARQL
Nu we een beetje een beeld hebben van de Knowledge Graph en hoe deze is opgebouwd, kunnen we het endpoint ook gaan bevragen middels SPARQL. Om te beginnen met een simpele query proberen we in eerste instantie om met adresgegevens (de postcode) alle objecten op te halen.
- In tegenstelling tot de registratieve endpoints hoeven we nu geen rekening te houden met historie. Deze versie van de Knowledge Graph heeft alleen de actuele situatie weer. Datzelfde geldt voor inactieve statussen.
- Er hoeven slechts drie objecten bij elkaar te komen om de geometrie, adresgegevens en objectgegevens respectievelijk te benaderen. In de reguliere combinatie tussen BAG, BRT en BGT zouden dit er vele malen meer zijn om dezelfde informatie op te halen.
- We hoeven niet zelf te zoeken naar connecties over datasets heen. Objecten die direct te integreren zijn zijn in deze weergave van de data reeds samengebracht.
Meer dergelijke eenvoudige queries hebben we voor de geïnteresseerde lezer samengebracht in een Data Story.
We kunnen de query ook nog iets complexer maken. Veel vragen die men wil beantwoorden vanuit een bepaalde (geografische afkadering). Daarbij gaat de voorkeur uit naar het gebruiken van administratieve links zoals deze in de data liggen.
In deze query:
- Maken we sprongetjes heen en weer tussen Places en Administrative area om te demonstreren hoe deze objecten verschillend, maar toch te onderscheiden zijn.
- Filteren we binnen een bepaalde woonplaats om alle adressen op te halen met een bepaalde typering (hier: Politiebureau)
- Grouperen we de resultaten op het onderliggende BRT polygoon zodat adressen worden geaggregeerd tot één object.
Tip: Wil je geholpen worden met je eerste query en deze op basis van natuurlijke taal opstellen? Probeer dan ook eens de Sparklis omgeving die we daarvoor hebben klaargezet.