KKG Generatie Proces
Het proces is in 2 grote stappen te splitsen.
- Het voorbereiden van de data in Databricks totdat deze klaar is omgeschreven te worden naar Linked data. In deze stap zijn er drie verschillende substappen:
- Het ETL van de PDOK bronnen tot de Databricks Catalog.
- Het creeeren van linksets tussen registraties op basis van geometry.
- Het creeeren van IMXGEO views op basis van joins op de verschillende registraties en linksets.
- Het omzetten van de tabulaire data tot linked data en inladen in een Triple Store. In deze stap zijn er vijf verschillende substappen:
- Het creeeren van een mapping bestand van tabulair naar linked data.
- Het omzetten van het mapping bestand tot het correcte format voor het daadwerkelijk uitvoeren.
- Het daadwerkelijk omzetten van de data uit de catalog tabellen naar linked data files.
- Een controle uitvoeren op de correctheid van de linked data files, met behulp van SHACL bestanden.
- Het laden van de linked data files en de controle resultaten naar een triple store.
Generiek Proces Methode
Het volledig generatie proces wordt uitgevoerd in Databricks. Databricks heeft een workflow module, hier ‘flows’ genoemd. De flows bestaan uit verschillende stapjes, of tasks binnen Databricks, die op basis van condities achter elkaar worden uitgevoerd. De taken bestaan uit Databricks Notebooks met vooral Python en Spark code. Uitgangspunt is het gebruik van generieke taken (flow stapjes) met parameters. Zodat verschillende registraties en de verschillende flows dezelfde notebooks gebruiken. Aanpassingen binnen een notebook gelden dan gelijk voor alle registraties.
Configureren flows
M.b.v. een API kunnen flows geconfigureerd worden vanuit een notebook. Per registratie staat er een notebook om de flow te creeeren. Deze maakt gebruik van generieke tasks met parameters.
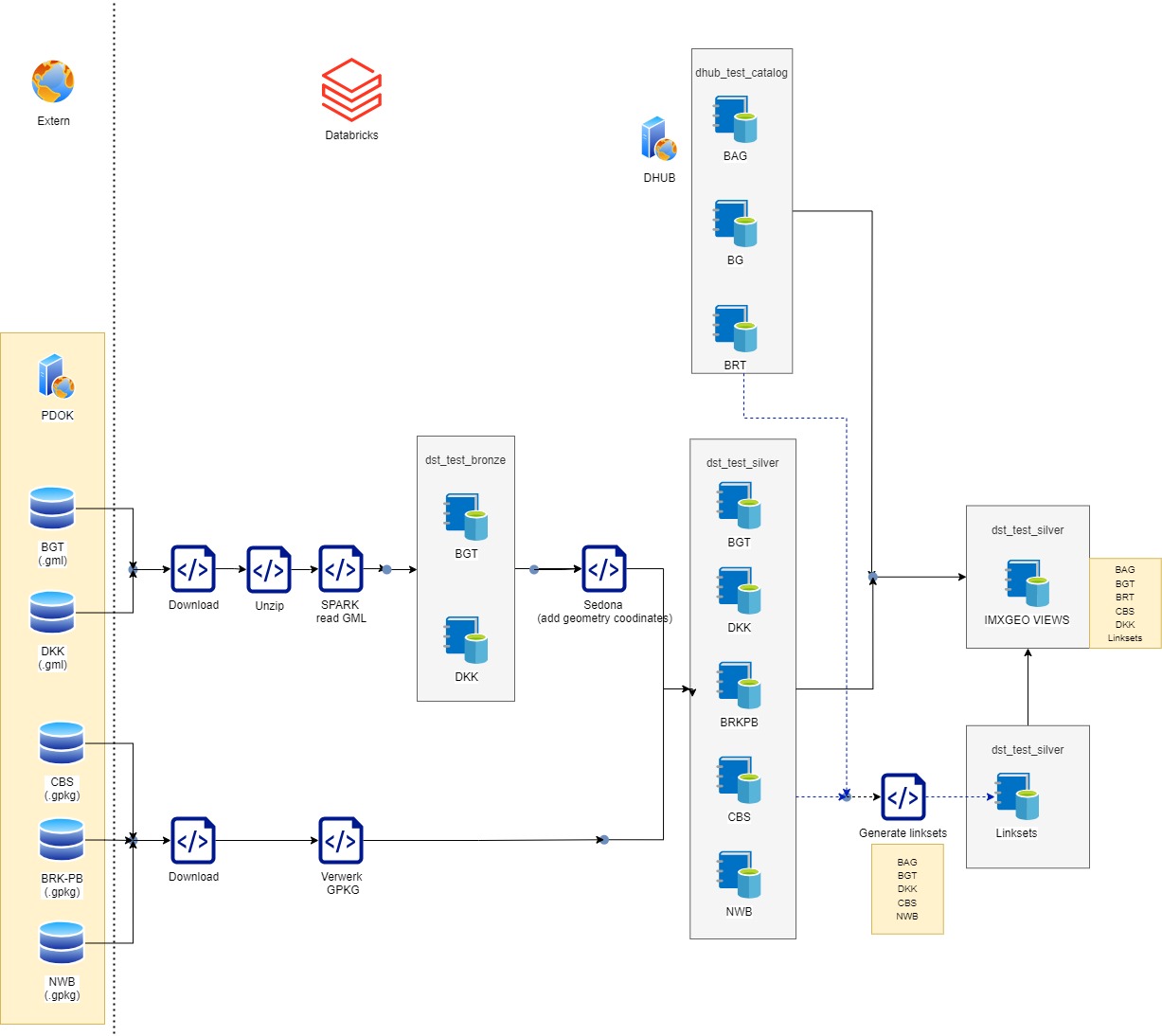
Flow 1: Lezen bronnen en verplaatsen naar Databricks unity catalog tables
Als de data nog niet beschikbaar is in de DataHub, is het noodzakelijk om de data voor te bereiden en deze te uploaden naar Databricks vanuit een PDOK-bron. Hiervoor zijn er twee formatopties, elk met hun bijbehorende taken.
1.1a. Inlezen GML bestand:
Tasks:
- Download. Het downloaden van een bestand naar een download volume in Databricks.
- Unzip. Het unzippen van GML bestanden naar een volume in Databricks.
- Spark read GML. Het uitlezen van een .gml bestand met behulp van Spark naar een unity catalog table. De catalog is bronze.
- Sedona (add geometry coordinates). Het toevoegen van de 4326 geometry en verplaatsen naar de silveren catalog.
1.1b. Of inlezen GPKG bestand:
Tasks:
- Download. Het downloaden van een bestand naar een download volume in Databricks.
- Verwerk GPKG. Het uitpakken van het .gpkg bestand en verplaaatsen naar de silveren catalog.
Zodra alle benodigde tabelgegevens beschikbaar zijn in een zilvercatalogus, kunnen de benodigde linksets worden gemaakt. Linksets zijn datasets die informatie uit twee verschillende bronnen combineren om de gegevens te integreren in de volgende stappen tijdens het maken van de KKG.
1.2. Creatie linksets:
Tasks:
- Generate linksets. De registraties worden aan gekoppeld op basis van geometry overlap. Dit genereert een linkset tabel met identificaties van 2 tabellen. Zit in de silveren catalog.
Om de KKG te genereren, wordt een set weergaven gemaakt in de Unity-catalogus. Deze weergaven aggregeren gegevens uit verschillende bronnen op basis van een gedefinieerde logica. Deze logica wordt beschreven in de IMX-Geo mappingbeschrijving.
1.3. Creatie IMXGEO views:
- Dit zijn views binnen de unity catalog. Waarbij onder andere verschillende registraties gekoppeld worden tot 1 view met behulp van de linksets. Deze views zijn de bron voor het IMXGEO model.
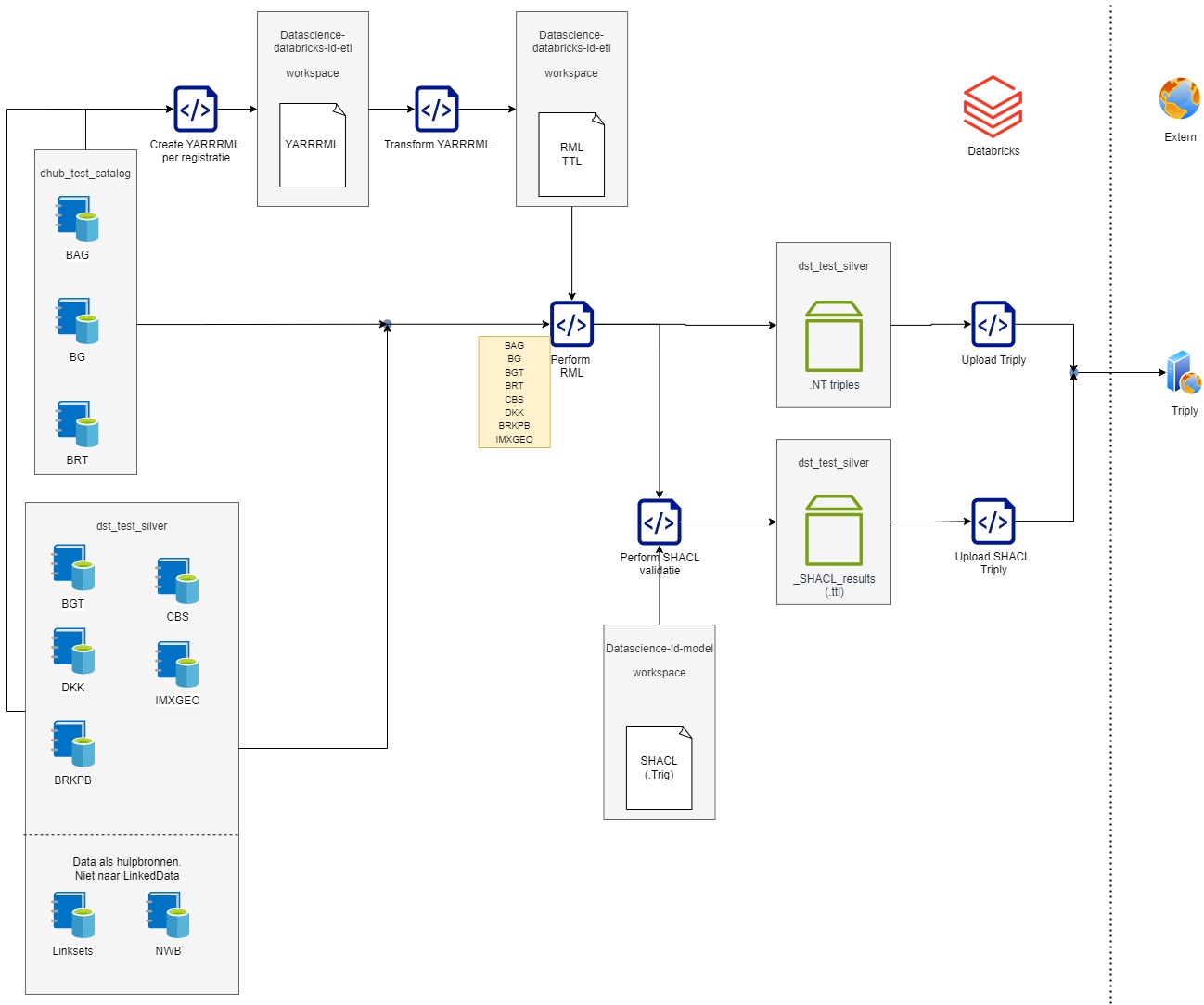
Flow 2: Transformeren van Databricks catalog tables naar Linked Data triples
Per registratie is er een flow om van tabulaire naar linked data te transformeren en up te loaden.
2.1 Creatie Mapping bestand van tabulaire data naar Linked Data:
Hiervoor maken we gebruik van de RDF Mapping language (RML). Dit beschrijft de mapping regels van heterogene data structuren naar RDF.
RML kan beschreven worden in bijvoorbeeld .ttl maar ook in yarrrml. YARRRML is beter leesbaar, maar dit werkt helaas niet met onze Python library om de mapping uit te voeren en de triples te genereren. Daarvoor is er een extra tussenstap voor de vertaling van de YARRRML files naar RML files.
https://rml.io/specs/rml/
https://rml.io/yarrrml/tutorial/getting-started/
Tasks:
- Create YARRRML per registratie. Dit zijn notebooks welke YARRRML files genereren op basis van unity catalog tabellen.
- Transform YARRRML. Het vertalen van de YARRRML naar RML in een .ttl format.
2.2 Genereren Linked Data
Op basis van de RML het uitvoeren van de vertaling van catalog tables naar triples in .nt format.
Tasks:
- Perform RML. De library ‘Morph_KGC’ voert de transformatie uit naar triples in .nt format.
https://morph-kgc.readthedocs.io/en/latest/
2.3 Valideren triples SHACL
De Shapes Constraint Language valideert RDF graphs tegen condities beschreven in de SHACL shapes. Dit valideert de triples binnen de .nt files.
Vanwege de compute kosten (veel geheugen) valideren we op dit moment enkele .nt files en niet de volledige set aan bestanden.
https://www.w3.org/TR/shacl/
Tasks:
- Perform SHACL validatie. Het uitvoeren van de SHACL validatie op enkele .nt bestanden gegeneeerd in de eerdere stap ‘Perform RML’.
2.4 Uploaden naar Triply
De gegenereerde triples, de validatie resultaten en de SHACL shapes worden geupload naar TriplyDB. Dit is een Linked Data database.
Tasks:
- Upload Triply. Het laden van de triples naar een graph in Triply.
- Upload SHACL. Het laden van de validatie resultaten en de SHACL shapes naar een graph in Triply.
2.5 Opzet repository
- Common folder: bevat de notebooks gebruikt als tasks in de flows.
- IMX-Geo folder: In deze folder bevinden zich naast de standaard items per registratie (de RML files, het notebook om de YARRRML te genereren, het notebook om de flow voor deze registratie te genereren) ook een notebook waarin de SQL queries voor de views beschreven staan.
Visualisatie flows
De onderstaande diagrammen visualiseren de hierboven beschreven flows.
Flow 1: Lezen bronnen en verplaatsen naar Databricks unity catalog tables.
Flow 2: Transformeren van Databricks catalog tables naar Linked Data triples