
Kadaster Knowledge Graph Technische Documentatie
Het doel van deze pagina is om informatie te verstrekken over de technische architectuur die de generatie van de Kadaster Knowledge Graph ondersteunt en, op de lange termijn, ook toegang te bieden tot de ontologieën en mappings die in deze generatie zijn gebruikt. Deze documentatie is een werkende voortgang en zal regelmatig worden bijgewerkt of verplaatst tot het einde van Q1 2025.
Indien u meer informatie wenst, kunt u contact opnemen met het Data Science Team van het Kadaster via het volgende e-mailadres: datascience@kadaster.nl.
Solution Architecture
Uiteindelijk streven wij ernaar onze data zo laagdrempelig en integraal mogelijk beschikbaar te stellen. Dat gaat uiteraard niet vanzelf. In zijn totaliteit onderkennen wij een Solution Architecture voor de totale ontsluiting. Deze zullen we in het volgende pagina toelichten.
Kernprincipes
Om tot deze solution architecture te komen zijn een aantal kernprincipes van belang die relevant zijn geweest in de totstandkoming. Deze principes zijn:
- Data komt zo dicht mogelijk bij de bron weg.
- Data lineage is van essentieel belang. Het moet bij alle data herkenbaar zijn waar deze zijn oorsprong vindt.
- Data is rijk aan metadata en semantiek. Dit is onderdeel van de data die wij ontsluiten.
- De Data Governance is duidelijk.
De volgende afbeelding geeft een overzicht van de totale solution architectuur voor de KKG.
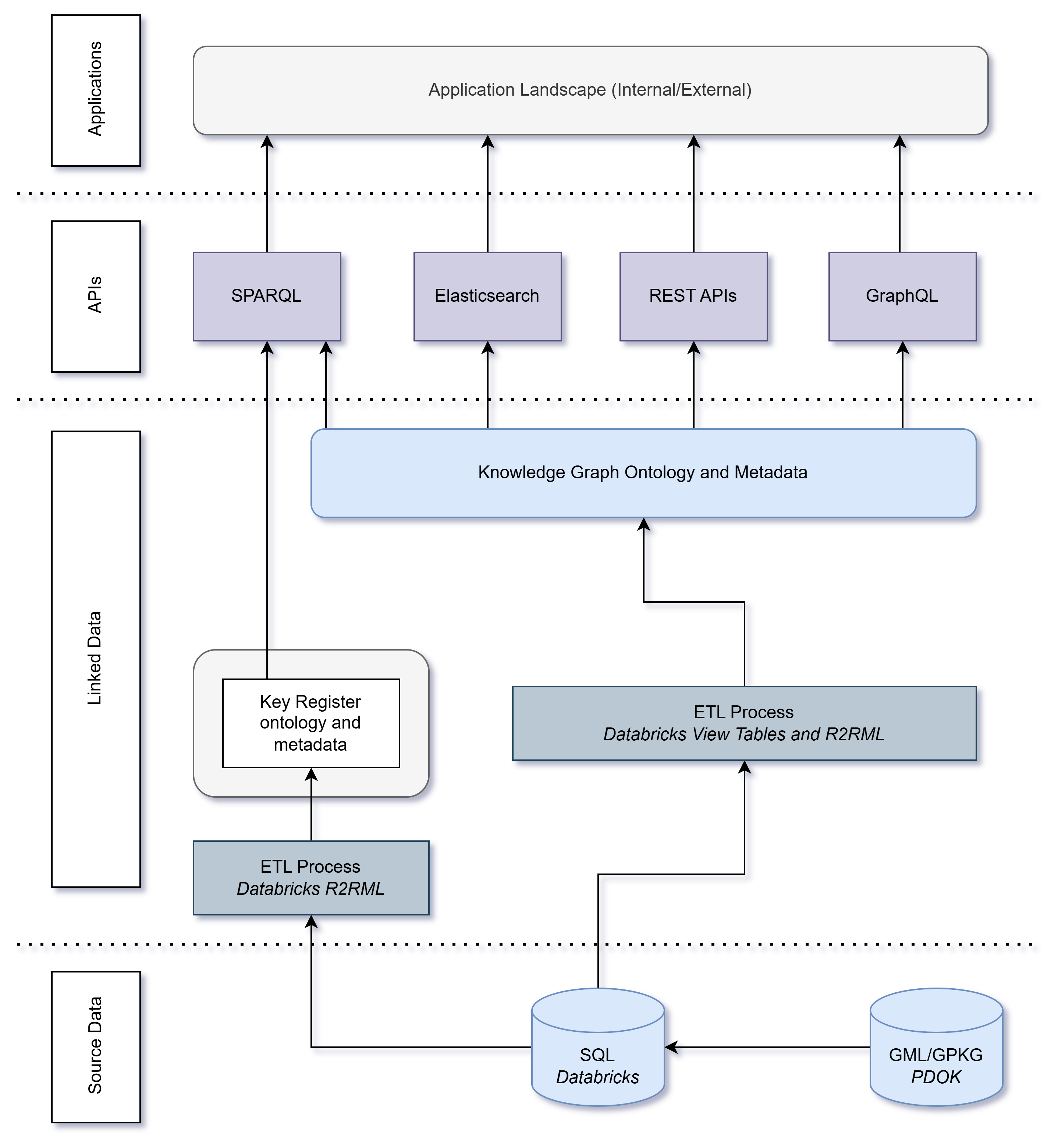
De oplossingsarchitectuur die wordt toegepast op de Kadaster Knowledge Graph is gelaagd. In de eerste laag worden brongegevens beschikbaar gesteld in een Databricks-instantie via DataHub, een centrale gegevensprovider voor gegevens die door Kadaster worden onderhouden, of via PDOK. Een meer gedetailleerde beschrijving van dit proces vindt u hier.
Zodra alle vereiste bronnen beschikbaar zijn in een Databricks-catalogus, worden View-tabellen gedefinieerd. Deze tabellen bevatten de logica die nodig is om de relationele gegevens van afzonderlijke sleutelregisters te projecteren en/of te aggregeren in één tabel ter voorbereiding op de transformatie van deze geaggregeerde gegevens naar gekoppelde gegevens. De projectie-/aggregatielogica wordt gedefinieerd op basis van de logica die is gedefinieerd door het IMX-Geo-mappingmodel. Zodra deze zijn gedefinieerd, wordt een transformatie- en laadproces uitgevoerd om deze informatie als triples in TriplyDB te laden. Meer informatie vindt u hier.
Na het laadproces wordt de KKG beschikbaar in de triplestore van Kadaster en wordt deze vergezeld door een SPARQL-eindpunt. Dit stelt gebruikers in staat om de KKG rechtstreeks te bevragen. Indien gewenst, kunnen gebruikers ook de SPARQL API gebruiken om data te integreren in externe applicaties. Toegang krijgen tot en gebruik maken van de informatie die beschikbaar is in de KKG wordt beschreven in deze tutorial.