Use Case: Generiek Kwaliteitsdashboard
Introductie
Als onderdeel van het uitwerken van een nieuwe architectuur voor het ontsluiten van zijn data heeft het Data Science Team gewerkt aan een tweetal demonstrators. Eén van deze demonstrators betreft de visie van het Kadaster over een generiek kwaliteitsdashboard. Al sinds jaar en dag is kwaliteit (in zekerheid en gebruik) één van de belangrijkste speerpunten van het Kadaster. Wij proberen de bronhouders en gebruikers van de data die wij beheren hierbij zo goed mogelijk te assisteren om de data zo kwalitatief mogelijk te brengen en houden.
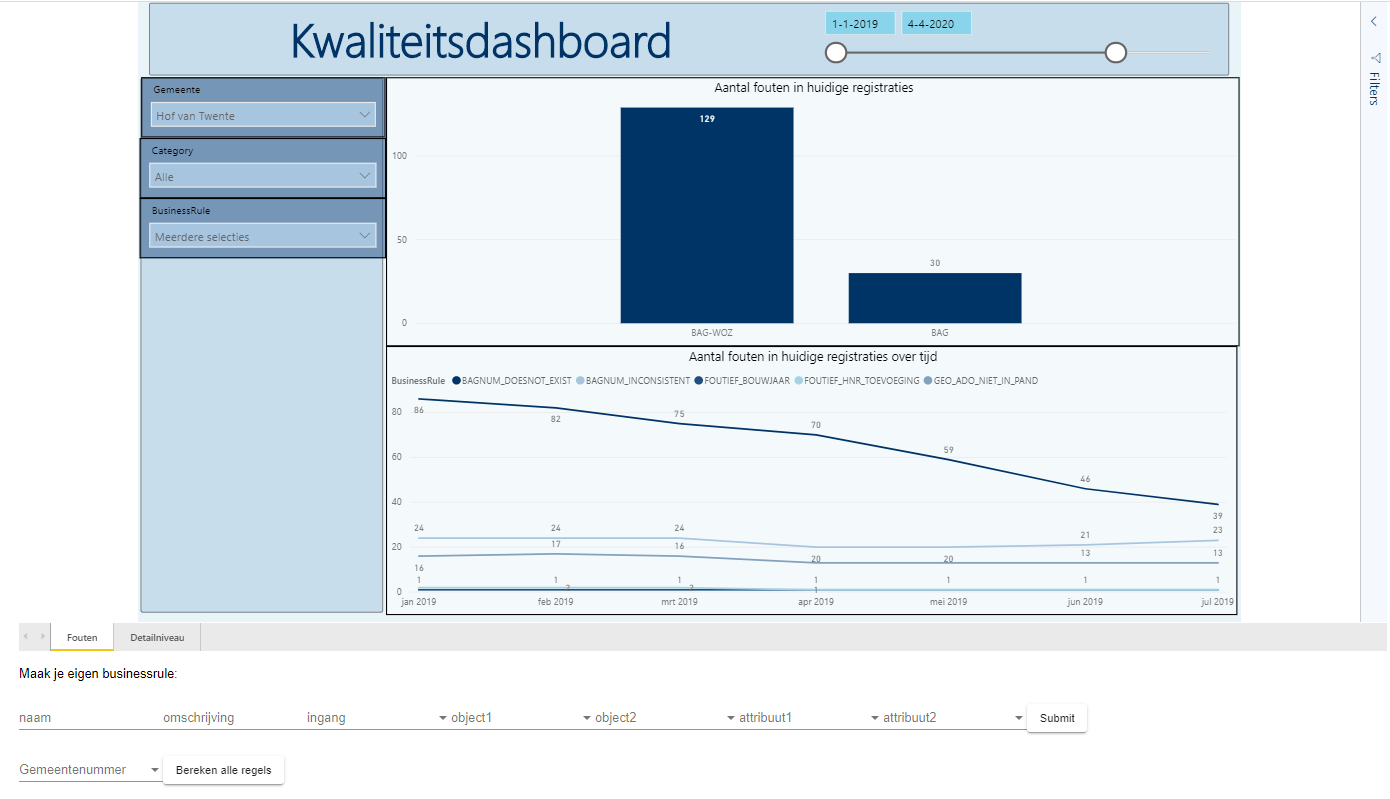
Een belangrijke tool hierbij zijn de kwaliteitsdashboards op de verschillende registraties, zoals die op de BAG en de BGT. Een voorbeeld vind je in Figuur 1. Hier melden we op basis van business regels op onze data mogelijke fouten terug richting de verscheidene bronhouders. We zien ook dat sinds de introductie van deze kwaliteitsdashboards, de kwaliteit van de registraties significant omhoog is geschoten. Toch zien we ook enkele tekortkomingen aan de huidige aanpak rondom deze kwaliteitsdashboards, namelijk:
- Wanneer een bronhouder een verbetering doorvoert over zijn registratie, is het resultaat hiervan pas een maand later in het kwaliteitsdashboard terug te zien, wanneer de analyse opnieuw gedraaid is.
- Alhoewel de business regels betreffende de kwaliteitsanalyse opgesteld zijn door ervaren domeinexperts van de verschillende registraties, zitten ze vaak verweven in de software en is het toevoegen of aanpassen van de regels niet triviaal voor de bronhouder.
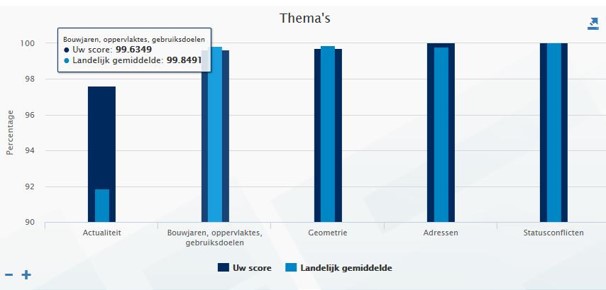
- Onze kwaliteitsdashboard zijn veelal registratie én product georiënteerd en buigen zich maar zelden over data kwaliteit tussen de verschillende registraties. Ze bieden geen integraal beeld over het Stelsel van Basisregistraties. «««< HEAD
-
Deze ontkoppeling tussen registraties zien we ook in de efficiëntie van de ontwikkeling van de kwaliteitsdashboards, waarbij ieder dashboard weer een op zichzelf staand product is met eigen teams, beheer en aanpak.
- Deze ontkoppeling tussen registraties zien we ook in de efficiëntie van de ontwikkeling van de kwaliteitsdashboards, waarbij ieder dashboard weer een op zichzelf staand product is met eigen teams, beheer en aanpak.
9fb78b2c5b8d92d0fd089a389640e7f4736bc907
Aanpak
Zoals bij ieder innovatie traject beginnen we door onszelf de vraag te stellen: Wat willen we precies bewijzen en wat levert het Kadaster op?
Het antwoord luidt als volgt. Kunnen wij de opzet neerzetten voor een generiek kwaliteitsdashboard waarbij:
- De analyse meer real-time plaatsvindt.
- Integrale kwaliteitsanalyse over registraties heen mogelijk is.
- De implementatie van de Business regels, kennis van het datamodel en het visualiseren van de resultaten kunnen modulair op een generieke manier worden toegepast.
Daarnaast hanteren we de volgende uitgangspunten:
- De demonstrators worden gevoed door (samengestelde) APIs over de verschillende basisregistraties in scope.
- De data waarover wordt gevisualiseerd en geanalyseerd blijft bij de bron. Voor deze toepassingen wordt geen kopie van de data gemaakt.
- De demonstrators tonen een doorkijkje naar de toekomst vanuit de architectuur/back-end, maar richten zich primair op de toepassing en waarde voor de eindgebruiker. Het toont een voorbeelduitwerking van hoe het Kadaster zijn data in de toekomst kan organiseren.
Scope van Demonstrator
Voor deze demonstrator is gekozen een beperkte scope te hanteren. In de analyse die we uitvoeren beperken we onszelf tot de volgende bronnen:
- Basisadministratie Adressen & Gebouwen (BAG)
- Waardering Onroerende Zaken (WOZ)
Een integrale koppeling tussen deze bronnen is tot dusver nog niet eerder gelegd in een kwaliteitsdashboard. Daarnaast is voor deze keuze gegaan omdat de combinatie een perfect voorbeeld is van twee bronnen die direct naar elkaar verwijzen (Immers, de WOZ aanslag wordt naar een adres verstuurd), maar beide bronnen worden in de huidige situatie als silo’s behandeld. Het doel is om minstens de volgende kwaliteitsregels aan het kwaliteitsdashboard toe te voegen:
- Onwaarschijnlijk bouwjaar (BAG) - Dit is een voorbeeld van een check op één attribuut binnen één object in één registratie. «««< HEAD
-
Onjuist gebruik van een letter in het huisnummertoevoeging veld (BAG) - Dit is een voorbeeld van een check op twee attributen binnen één object in één registratie.
- Onjuist gebruik van een letter in het huisnummertoevoeging veld (BAG) - Dit is een voorbeeld van een check op twee atrributen binnen één object in één registratie.
9fb78b2c5b8d92d0fd089a389640e7f4736bc907
- Nummeraanduiding zonder gerelateerd adresseerbaar object (BAG) - Dit is een voorbeeld van een check tussen twee objecten in één registratie.
- Verblijfsobject ligt niet in pand - Dit is een voorbeeld van een geometrische check tussen twee objecten in één registratie.
- Nummeraanduiding zonder gerelateerd WOZ-object (BAG+WOZ) - Dit is een voorbeeld van een check tussen twee objecten in twee registraties.
- Nummeraanduidingen in de BAG en WOZ met inconsistente data (BAG+WOZ) - Dit is een voorbeeld van een check op twee attributen tussen twee objecten in twee registraties.
Datamodel van de registraties en integrale bevraging
In bovenstaande introductie praten we voornamelijk over functionele eisen die wij aan onze demonstrator stellen. Uiteraard is er ook een techniek waarmee we deze demonstrator bewerkstelligen. «««< HEAD Om geïntegreerd en real-time bevragingen te kunnen uitvoeren maken wij gebruik van de querytaal GraphQL. GraphQL is een graaf-gebaseerde API waarmee ======= Om ge-integreerde en real-time bevragingen te kunnen uitvoeren maken wij gebruik van de querytaal GraphQL. GraphQL is een graaf-gebaseerde API waarmee
9fb78b2c5b8d92d0fd089a389640e7f4736bc907 een verscheidenheid aan bronnen integraal mee beschikbaar wordt gesteld.
Een graaf gebaseerd datamodel bestaat uit, net als in Linked Data, uit objecten en diens attributen. Wanneer we ons datamodel voor deze demonstrator visualiseren krijgen we een beeld zoals in Figuur 2.
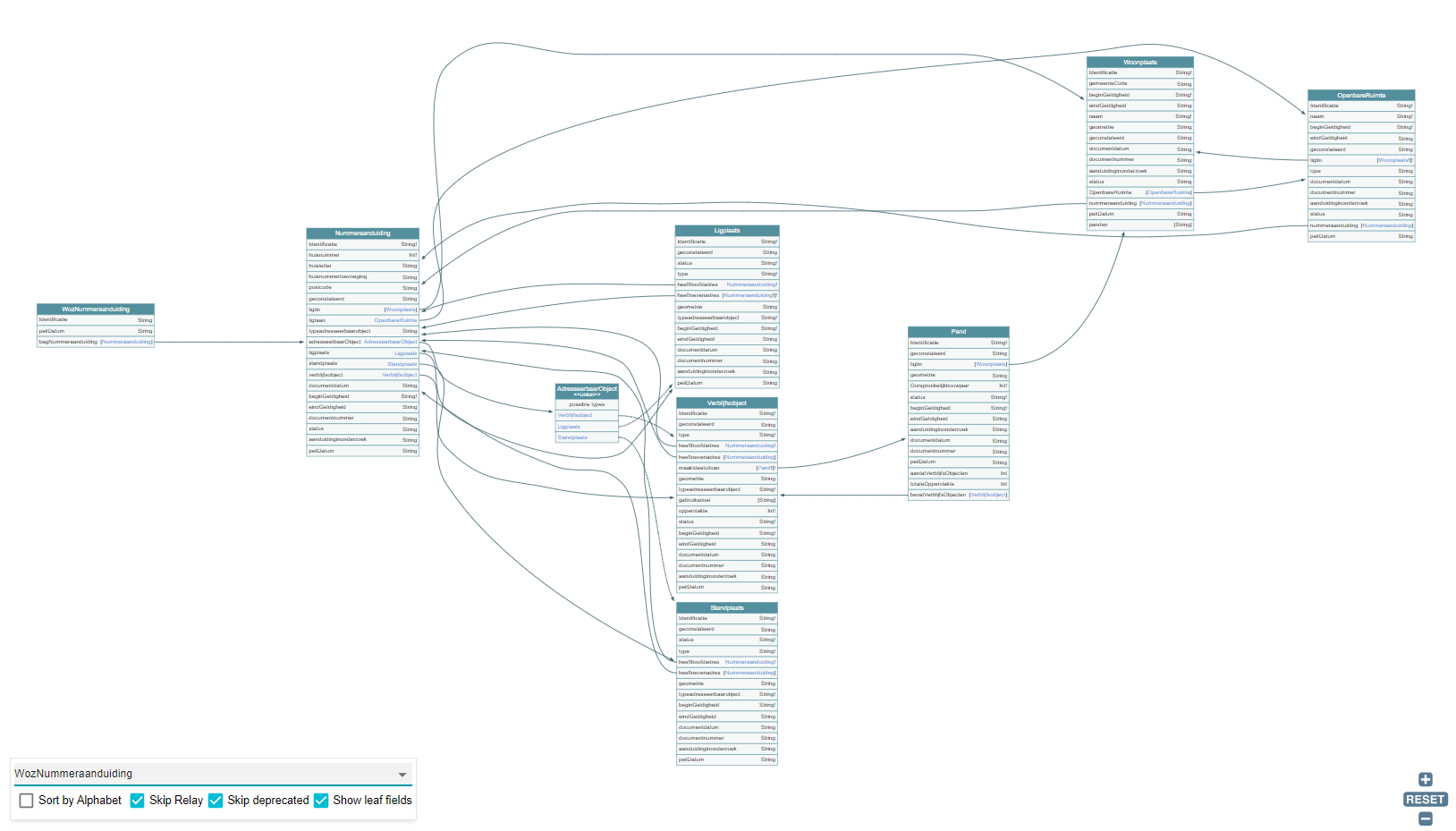
In GraphQL, net als in een reguliere REST API, is het belangrijk een bepaalde ingang te definiëren. Neem als voorbeeld de BAG-API. Ook hier is het gemakkelijk om informatie op te vragen over één object, zoals de informatie van één Pand of Nummeraanduiding. In GraphQL is dit in theorie niet anders. Het is dan ook gemakkelijk om te zien hoe GraphQL, net als een reguliere REST-API, goed om kan gaan met enkelvoudige object-georiënteerde bevragingen.
Voor een kwaliteitsdashboard werkt het net iets anders. Daar willen we een grootschalige set objecten achtereen analyseren en de resultaten opslaan. Denk bijvoorbeeld aan alle objecten binnen één gemeente. Hiervoor voegen we een extra ingang toe, zijnde de ingang voor een gemeente. Omdat een grote gemeente dusdanig veel objecten bevat dat het niet gewenst is dat alle resultaten over één HTTP-Request worden verstuurd, voegen we hierbij ook paginatie toe. (Oftewel, het bevragen van objecten in batch). Een sterk uitgeklede variant van een dergelijke bevraging zie je in Figuur 3.
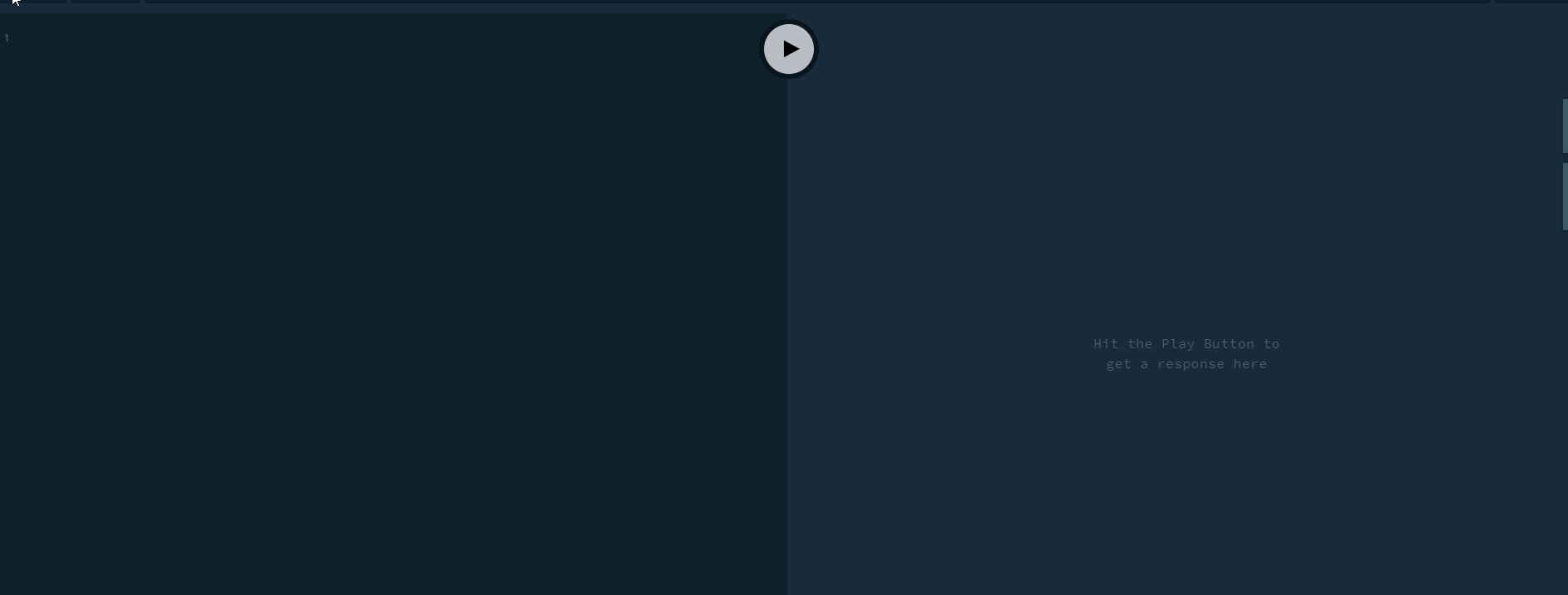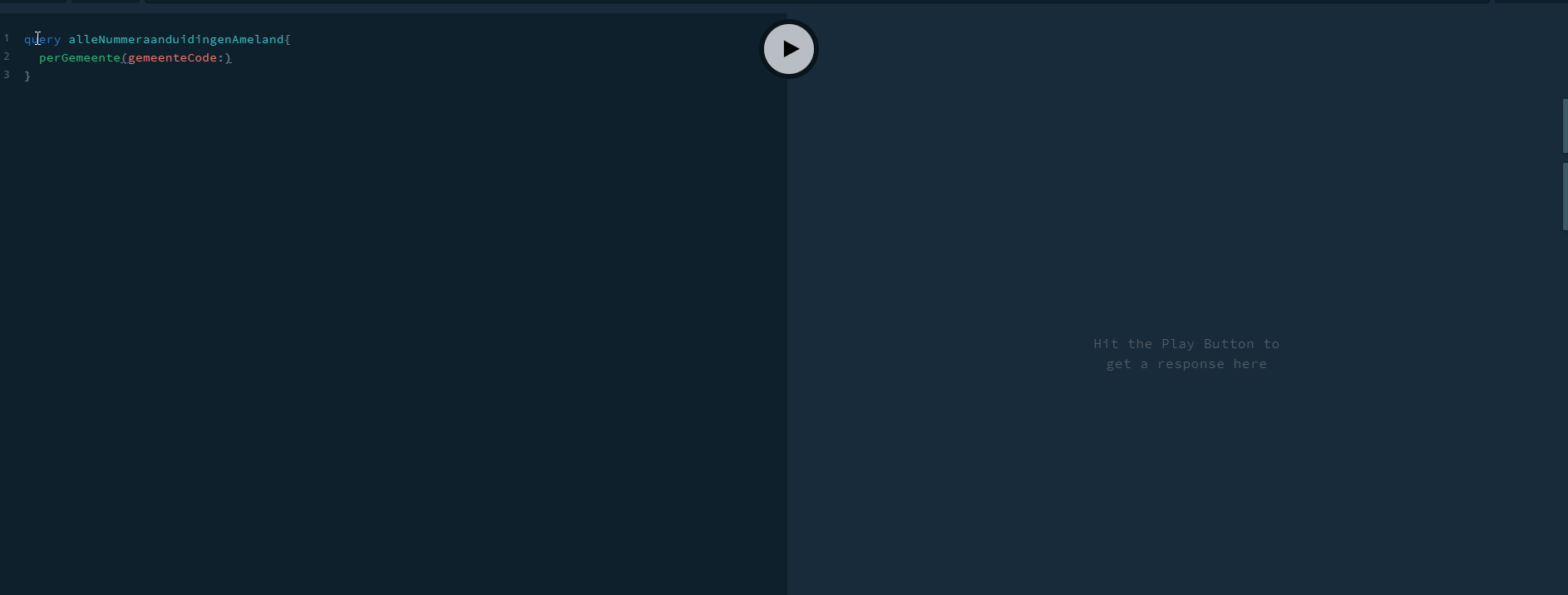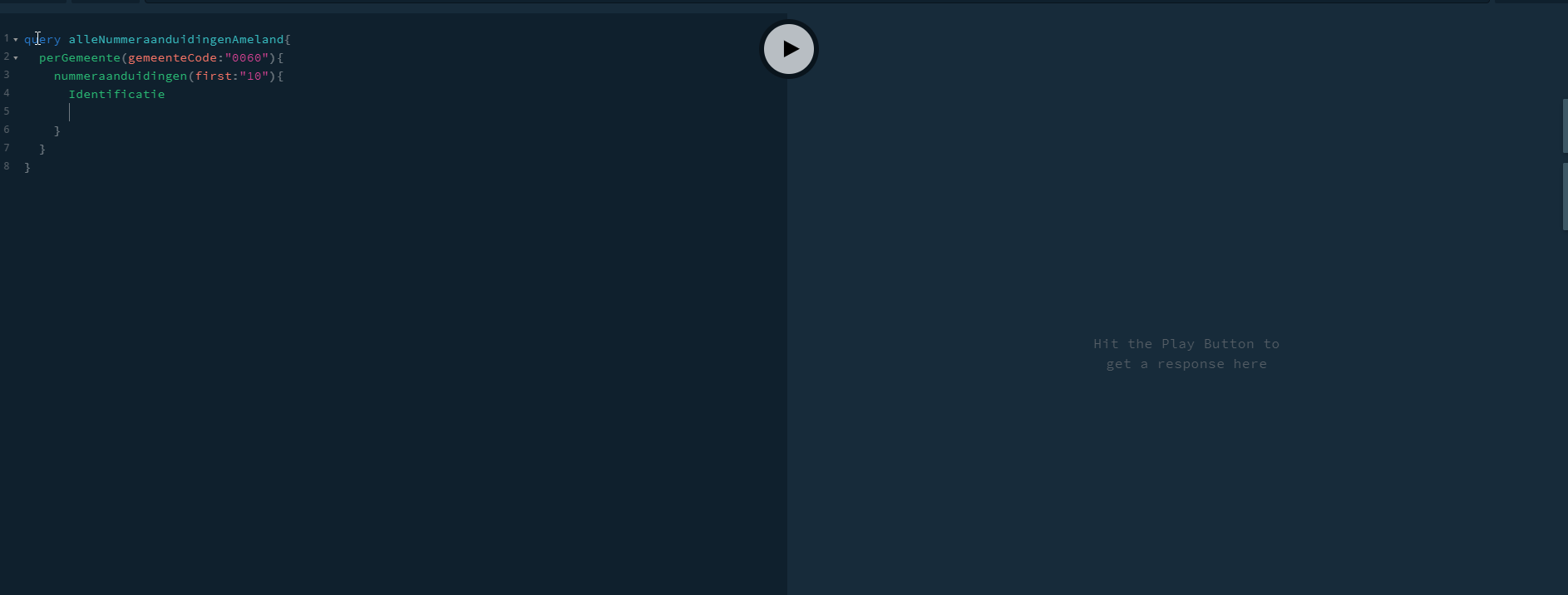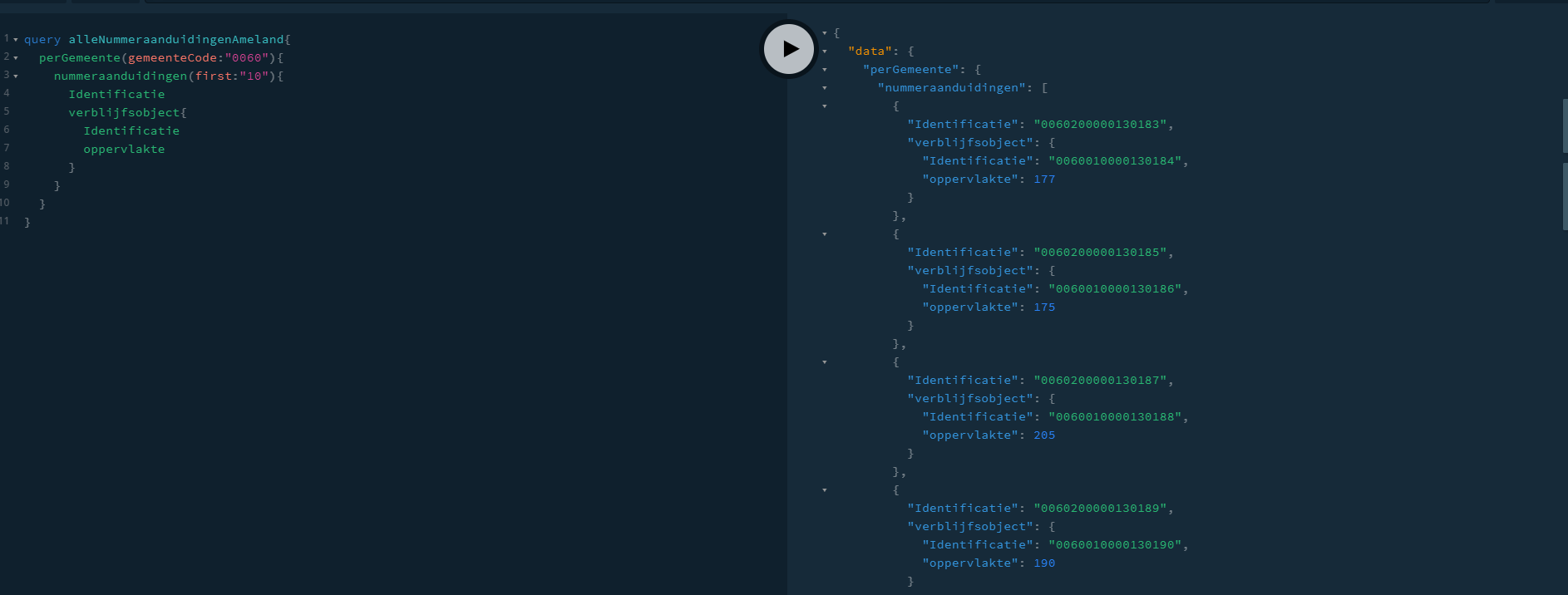
Mutaties bevragen versus een full check over een gemeente
De huidige demonstrator maakt gebruik van een vrij naïeve manier van data bevraging. Wanneer een bronhouder of andere gebruiker de kwaliteitsanalyse herstart, worden alle objecten van deze gemeente opnieuw bevraagd. In de praktijk wil je alleen een incrementele check uitvoeren, waarbij alleen de objecten worden bekeken die wijzigingen hebben doorgevoerd sinds de laatste refresh. We benadrukken dat het bevragen van deze mutaties het gewenste toekomst scenario is. Voor deze demonstrator was het buiten scope.
Business Regels over de bevraagde data en de rule engine
Nu we het met GraphQL mogelijk hebben gemaakt de data te bevragen die we nodig hebben voor een integrale BAG-WOZ vergelijking, is het tijd de business regels toe te voegen en de service die de daadwerkelijke vergelijking over de gevraagde objecten uitvoert. Dit is een microservice (gehost in Docker, gemaakt in Python), die op basis van beperkte input (Gemeentecode en een peildatum, indien men wil kijken op een eerder moment in de tijd) alle objecten bevraagd en tegen de ge-implementeerde business regels aan houdt.
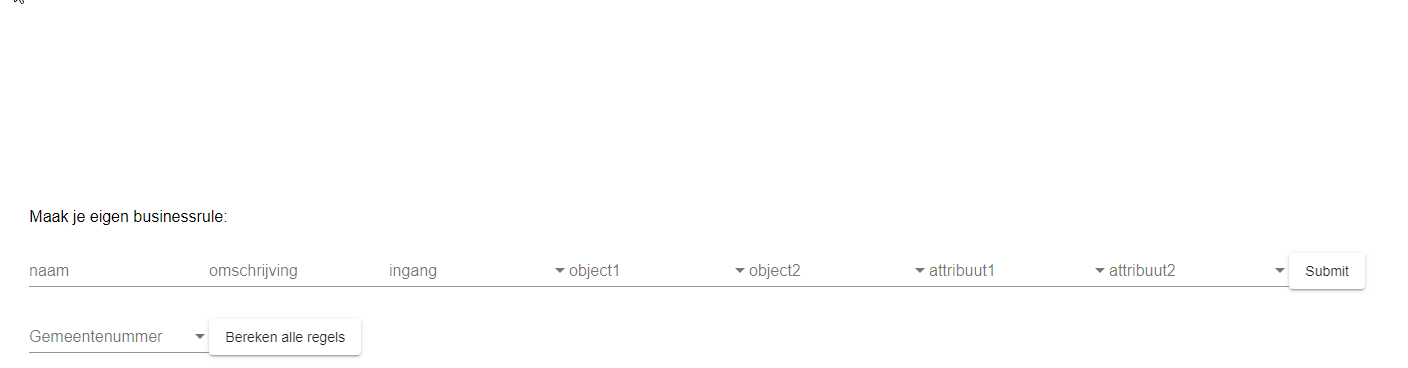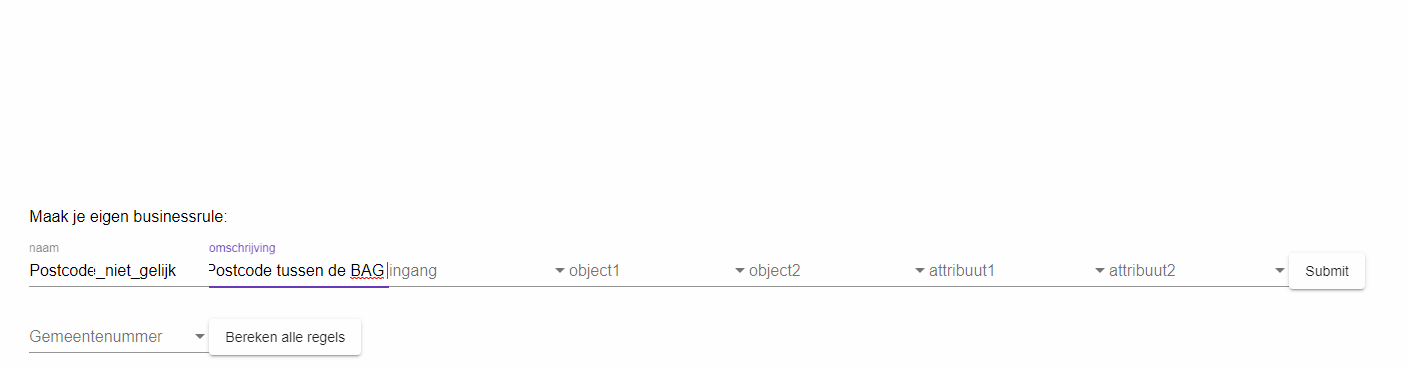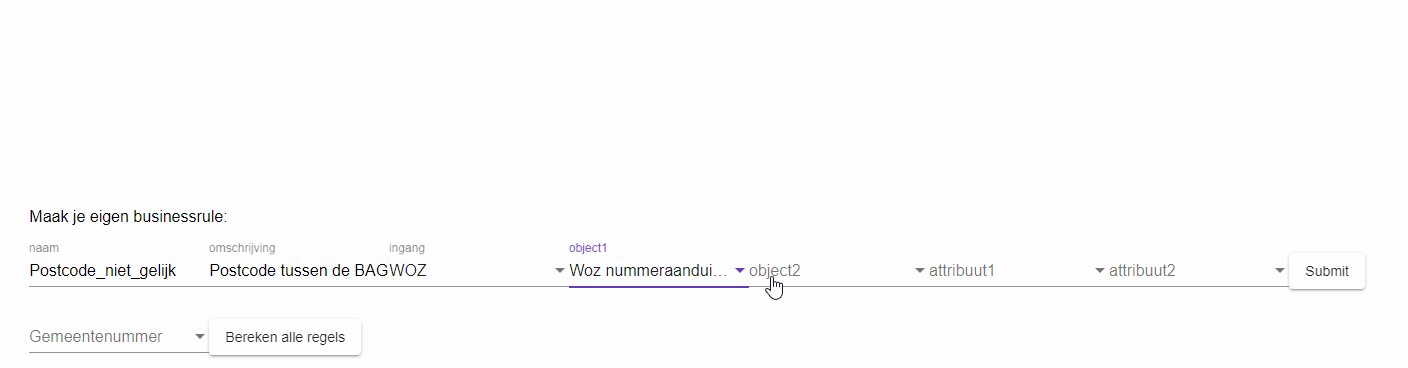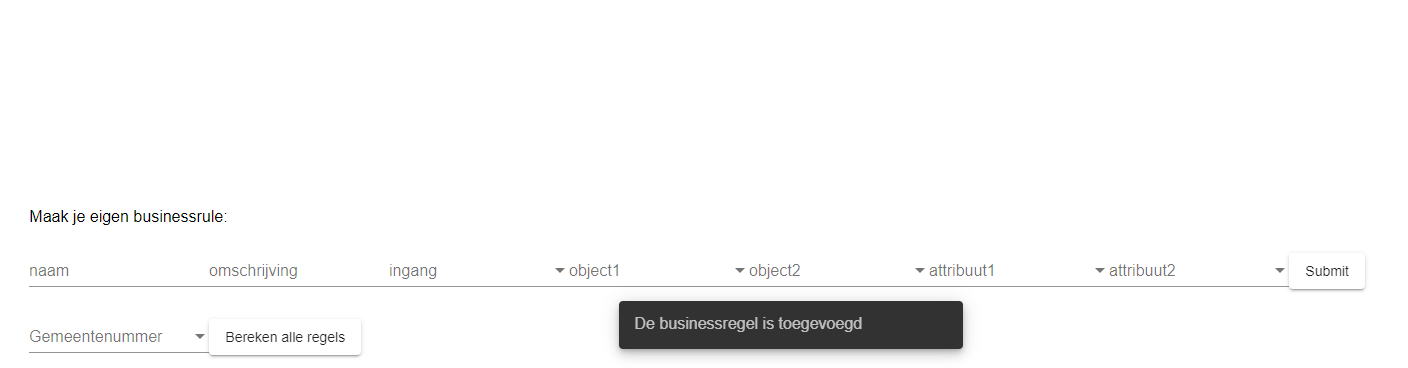
Het doel is om de business regels hier veelal een vorm van configuratie te laten zijn. Immers, het datamodel is bekend en gekoppeld aan de bevraging. Initieel zijn er een aantal regels in de software gezet door de developers, lijkend op de huidige situatie bij het Kadaster. Dit werkt voor de standaard regels, maar is weinig innovatief. Daarom is er in het laatste stuk van deze demonstrator gewerkt aan een zgn, Rule Engine. Om business regels generiek te implementeren is momenteel de huidige informatie nodig:
- INGANG: De ingang waarover de vergelijking moet worden gedaan (Willen we alle nummeraanduidingen langslopen? Of juist alle panden? Of wellicht alle WOZ-objecten). Deze keuze bepaalt welke objecten er wel en niet worden overwogen.
- OBJECT1: Het object waarover je wil vergelijken
- OBJECT2: (Evt.) het object waarmee je het wil vergelijken
- ATTRIBUTE1: Het attribuut van het object wat je wil vergelijken
- ATTRIBUTE2: (Evt.) Het attribuut waarmee je het wil vergelijken (van een ander object of bijvoorbeeld een scalar
- VERGELIJKING: Hoe je het wil vergelijken. Moet het gelijk zijn? Of juist niet gelijk? Of moet de ene waarde lager zijn dan de ander? Etc.
We hebben deze kennis omgezet naar een eerste versie van een Rule Engine, dat over alle WOZ Objecten en over alle Nummeraanduidingen heen kan lopen. Hierop leest de engine de beschikbare objecten en attributen uit uit het schema en vraagt het de gebruiker een keuze te maken tussen de objecten en attributen welke vergeleken moeten worden. Hierbij doet hij op dit moment standaard een vergelijking of de gekozen attributen gelijk zijn, maar dit is in de toekomst gemakkelijk uit te breiden naar gecompliceerdere vergelijkingen.
Een visuele weergave van de Rule Engine vind je in Figuur 4.
Visualiseren van de kwaliteitsanalyse
Wanneer de bevraging mogelijk is en een framework staat voor de business rules kunnen we toe naar het daadwerkelijke dashboard. We hebben gekozen voor een standaard BI tool om dit te bewerkstelligen. Immers, het doel is een generiek kwaliteitsdashboard en iedere afnemer/bronhouder zal in de praktijk zijn eigen tools en processen hebben om zijn kwaliteit te verbeteren. In deze demonstrator benadrukken we dat het Kadaster primair moet zorgen dat het de middelen levert om kwaliteitsanalyses te kunnen doen richting een gemeente en daarbij de vrijheid moet laten aan de bronhouder om dit in zijn eigen proces te passen. Voor deze demonstrator hebben we gebruik gemaakt van PowerBI.
Een screenshot van het dashboard is te vinden in Figuur 5. Hierbij vind je een uitknipsel van het dashboard zelf, maar ook van de ververs knop voor een gegeven gemeente.
Deze ververs knop staat in connectie met de Microservice dat de bevragingen en vernieuwing van de data realiseert. Op deze manier kan een bronhouder real-time zijn verbeteringen
aan zijn registratie terug zijn in het kwaliteitsdashboard.