
Lock-Unlock: Lock de Data, Unlock het Potentieel
Project Achtergrond
Het Lock – Unlock project is uitgevoerd in opdracht van het Federatief Datastelsel, programmaonderdeel van Realisatie IBDS. Binnen het Federatief Datastelsel is het kunnen delen van data uiteraard de kern, maar dit moet ook op een verantwoorde manier gebeuren, waarbij bescherming van data en autorisatie belangrijk zijn.
Lock-Unlock richt zich op Linked Data, voortbouwend op de Integrale Gebruiksoplossing (IGO) en de Kadaster Knowledge Graph (KKG) ontwikkeld door het Kadaster. Er zijn weinig gestandaardiseerde mogelijkheden voor autorisatie van data in het Linked Data domein. Dit project is uitgevoerd om de (on)mogelijkheden te onderzoeken en te testen.
Resultaten



Lock-Unlock Infographic
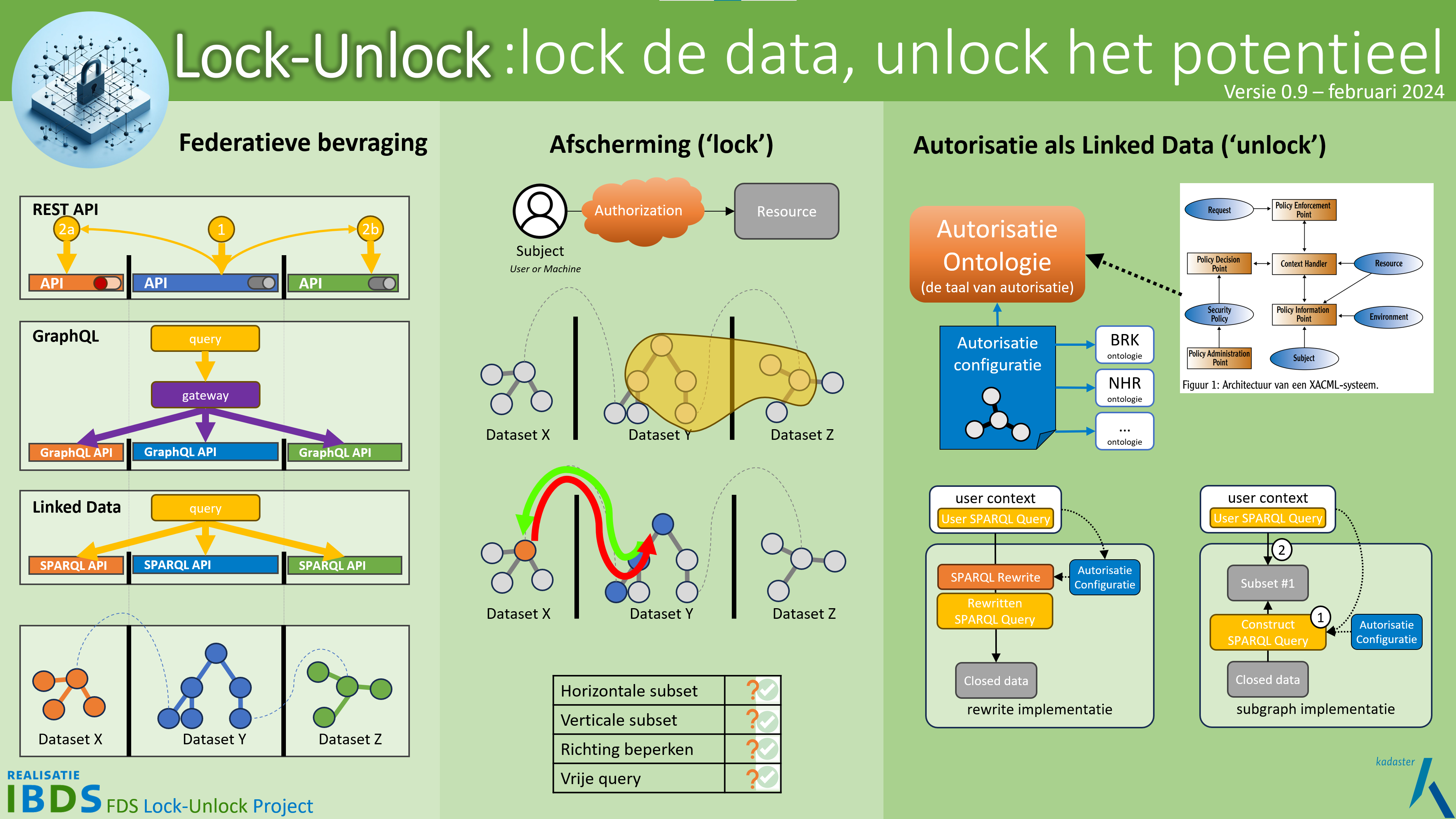
Het Lock-Unlock-project bestaat uit drie bouwstenen:
Federatief Bevraging
Een federatief datastelsel betekent natuurlijk ook het federatief kunnen bevragen van de verschillende datasets. Dit bevragen is uitsluitend mogelijk via een API. Er zijn verschillende opties voor APIs, namelijk Rest API’s, GraphQL API’s en SPARQL API’s voor het bevragen van Linked Data. Een belangrijk verschil tussen die verschillende opties is de “query vrijheid”:
- Bij REST API’s definieert de aanbieder wat je kan bevragen en hoe.
- Bij GraphQL is in een hiërarchisch GraphQL schema vastgelegd hoe dat opgevraagd kan worden en met een GraphQL gateway kan dat zelfs over meerdere GraphQL endpoints. GraphQL is daarmee flexibeler dan REST API’s en maakt het mogelijk om integraal informatie beschikbaar te stellen.
- Een SPARQL API is gebaseerd de mogelijkheden van Linked Data. In Linked Data is data expliciet voorzien van metadata zodat het duidelijk is wat elk element betekent. Dit is geen hiërarchisch schema, maar er kunnen vrije combinaties en relaties worden bevraagd. SPARQL is de query taal die dit ‘vrij bevragen’ mogelijk maakt en ondersteunt direct het bevragen van meerdere endpoints in samenhang vanuit een enkele bevraging (query).
Afscherming (‘Lock’)
Binnen een federatief datastelsel zullen er ook gesloten/afgeschermde datasets zijn waardoor het kunnen afschermen van data en het autoriseren van gebruikers belangrijk is. Voor het Lock-Unlock project hebben we daarom een aantal requirements voor de autorisatie oplossingen opgesteld: het kunnen werken met horizontale (bijv. een specifieke regio) en verticale (bijv. wel/geen koopsom) subsets en het kunnen beperken van de richting waarlangs een query van element (node) naar element bevraagt. Tegelijkertijd willen we de vrije query mogelijkheden (de kracht van Linked Data) blijven ondersteunen.
Autorisatie als Linked Data (‘Unlock’)
Op basis van die requirements zijn we tot het Autorisatie als Linked Data concept gekomen. Dit houdt in dat de autorisatie zelf als Linked Data wordt uitgedrukt. Daarvoor zijn twee onderdelen nodig: een autorisatie ontologie en een autorisatie configuratie. De autorisatie ontologie is een “woordenboek” welke de autorisatie terminologie bevat. Deze hebben wij gebaseerd op XACML. De autorisatie configuratie bevat de specifieke autorisatie regels voor een resource. Op basis hiervan zijn 2 implementaties bedacht en getest: de subset implementatie en de SPARQL rewrite implementatie (zie demonstrators tegel voor meer informatie hierover).
- Bij de subset methode wordt op basis van de autorisatie configuratie on demand een subset gecreëerd. Op deze subset wordt vervolgens de query van de gebruiker uitgevoerd.
- Bij de SPARQL rewrite methode wordt de binnengekomen query gecontroleerd en herschreven (meestal uitgebreid) op basis van de autorisatie configuratie en vervolgens naar de onderliggende data gestuurd zodanig dat de resultaten worden beperkt tot de data waartoe de gebruiker toegang heeft.