
Use Case: Missende BAG-waarden voorspellen
Introductie
Kadaster is beheerder van de Basisadministratie Adressen & Gebouwen (BAG). Deze administratie wordt door de bronhouders, de gemeenten, bijgehouden en gebruikt voor een scala aan (maatschappelijke) toepassingen. Deze gemeenten streven er natuurlijk naar om alle informatie die in deze administratie gaat zo goed mogelijk te onderhouden en dus kijkt het ook doorlopend naar mogelijkheden om de kwaliteit van zijn data te verbeteren. Daarbij kijkt het ook naar opkomende technologieën zoals Machine Learning en Artifical Intelligence. Deze use richt zich op de gemeente Amsterdam, dat voor een aantal adressen in zijn gemeente niet de precieze oppervlakte en/of het bouwjaar weet. Denk hierbij aan panden met een bouwjaar van 5. Een afstudeerder bij het Kadaster heeft zich bezig gehouden met de vraag: Kunnen we onwaarschijnlijke of missende BAG-waarden omtrent oppervlakte en bouwjaar voorspellen aan de hand van een voorspellend model?
Het doel
Het doel van deze use case was om een voorspellend model te maken dat, gegeven een combinatie van interne en externe gegevens, het bouwjaar en oppervlakte van BAG-objecten kan voorspellen. Deze voorspellingen kunnen we dan weer gebruiken om:
- Missende waarden in de BAG alsnog van waarden te voorzien
- Waarden die ver afwijken van de voorspelling te Identifier en mogelijk verder onderzoeken
Aanpak
Eerst beginnen we met het ophalen van de data. In eerste instantie gebruiken we hiervoor twee bronnen: de BAG en de Wet Onroerende Zaken (WOZ). De waarde van een huis kan een indicatie geven van de grootte en/of de leeftijd/monumentaliteit van een gegeven huis. Daarna proberen we door middel van het meest simpele model (Een lineaire regressing) te kijken of er al nuttige dingen te zeggen zijn over de data zonder al te veel verwerking. Data verwerking en modellering doen we in de programmeertaal R. Deze resultaten bieden hoop op een succesvolle voorspelling en dus gaan we over naar ingewikkeldere transformaties en modellen. Vanuit de BAG berekenen we voor het object (adres) onder consideratie de gemiddelde oppervlakte/bouwjaar van (de rest van) de straat en voegen deze toe als verklarende factor. Ditzelfde doen we voor de gemiddelde oppervlakte/bouwjaar van de buurt, alleen splitsen we deze uit op de functie van het object. In de BAG onderscheiden we voor een verblijfsobject (adres) de volgende functies:
- Bijeenkomstfunctie
- Celfunctie
- Gezondheidszorgfunctie
- Industriefunctie
- Kantoorfunctie
- Logiesfunctie
- Onderwijsfunctie
- OverigeGebruiksfunctie
- Sportfunctie
- Winkelfunctie
- Woonfunctie
Tenslotte voegen we ook data toe omtrent de afstand tot het centrum van de stad. De hypothese is dat gebouwen midden in het klassieke centrum van Amsterdam vermoedelijk ouder zijn dan die in de nieuwbouwwijken aan de rand van de stad, ceteris paribus.
Met de nieuwe ge-transformeerde data testen we ook nieuwe type modellen. De meest veelbelovende modellen zijn het Random Forest model en de Logistische regressie. De resultaten van deze modellen presenteren we in de volgende alinea.
Het resultaat
Uiteindelijk is er gekozen voor het random forest model als het beste model voor deze specifieke uitdaging. Er wordt gebruik gemaakt van 100 beslisbomen met 2 random geselecteerde variabelen per vertakking. De belangrijkste voorspellende variabelen zijn het gemiddelde bouwjaar van panden in een buurt en de afstand tot het centrum; zij verklaren 90% van de variantie in bouwjaren. De gemiddelde afwijking van de schatting in bouwjaren bedraagt 0,75%. Oppervlakten van verblijfsobjecten worden voornamelijk geschat aan de hand van de WOZ-waarde van een object en gegevens over het oppervlak van objecten in een straat,, buurt en met een vergelijkbare gebruiksfunctie. Dit model verklaart 54% van de variantie in oppervlakten en de gemiddelde afwijking van de schatting bedraagt 31%. Bij objecten met een woonfunctie 7%.
Er is nog geprobeerd het model te verrijken met een Google Streetview foto’s van de adressen. Hiermee zouden we bijvoorbeeld bouwstijlen of monumentaliteit kunnen achterhalen van een adres. Echter bleek dit een te tijdrovend en computrationeel zware uitdaging te zijn om te doen in de tijd die de student voor dit onderzoek had. Dit zou nog wel een aandachtspunt zijn voor de toekomst om het model nog verder te verbeteren.
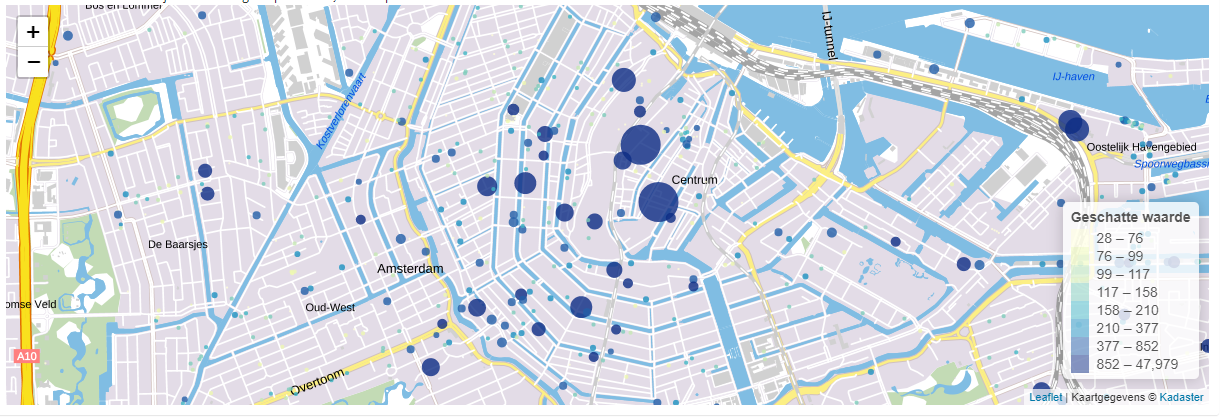
We hebben ervoor gekozen de uiteindelijke resultaten te delen met de gemeente Amsterdam in de vorm van een (Excel)-lijst met voorspellingen en een interactief R Shiny dashboard, waarin ze op een gebruiksvriendelijke manier de resultaten voor hun stad kunnen inzien. Een live demo van deze resultaten kun je vinden via deze link.
R, RStudio & R Shiny dashboards
Deze analyse hebben we uitgevoerd in de statistische open-source analyse-tool R. Deze taal heeft de laatste jaren wereldwijd aan populariteit gewonnen door zijn gebruiksgemak, levende community en mogelijkheden. RStudio is een Interactive Development Environment (IDE) waarmee we het gebruiksgemak voor ons als developer vergroten. R Shiny is tenslotte de open-source dashboarding package waarmee het mogelijk gemaakt wordt om snel dynamische en interactieve dashboards te maken voor eindgebruikers.