
Use Case: Kwaliteit van aktes uit een OCR traject
Introductie
Binnen het Kadaster heeft een aantal jaren terug een grootschalig onderzoek plaatsgevonden waarbij de bestaande akten sinds 1950 geanalyseerd werden. Het doel was de erfdienstbaarheden uit deze akten te herkennen en hiermee het onderzoekend werk van de bewaarder te vergemakkelijken. In de laatste jaren zijn er - mede ingegeven door de huidige technologische vernieuwingen - meer en meer standaarden en eisen aan een akte opgesteld. Vroeger was dit een stuk minder vanzelfsprekend. Zo waren veel akten handgeschreven of kwam het van een ouderwetse typmachine, en werd er regelmatig het een of ander buiten de lijntjes bij de aktetekst opgeschreven. Al deze akten zijn bij het Kadaster gedigitaliseerd door deze te scannen en de resulterende scans digitaal op te slaan.
Om het bovenstaande onderzoek te bespoedigen is er een vorm van Optical Character Recognition (OCR) toegepast op de gedigitaliseerde scans, om hierna analyses uit te kunnen voeren op de ge-extraheerde tekst. Alhoewel zeer bruikbaar voor dit onderzoek zijn deze ge-extraheerde akteteksten nadien in de vergetelheid geraakt. Het Emerging Technology Center (ETC) en het Data Science Team (DST) zijn recent opnieuw in deze akteteksten gedoken om te zien of deze wellicht voor nieuwe toepassingen bruikbaar kunnen zijn. Daarbij waren er een aantal vragen vitaal:
- Zijn de ge-extraheerde akteteksten leesbaar of bevatten deze voornamelijk ruis?
- Zijn de akteteksten bruikbaar voor een domeinexpert? I.e. zijn de belangrijkste details terug te vinden in de aktetekst?
- Is de techniek van een aantal jaren geleden (2006, red.) voldoende of bieden nieuwe OCR technieken wellicht een beter bruikbaar geheel?
Optical Character Recognition (OCR)
Optical Character Recognition is de techniek waarmee een computer scans of foto’s omzet naar een leesbare gestructureerde tekst. In dit specifieke geval betreft het scans van fotokopieën van akten uit het openbaar register bij het Kadaster.
Een samenvatting
Voor een simpele visuele samenvatting verwijzen we de lezer naar Figuur 0. Voor een meer in-depth discussie van de gebruikte technieken en resultaten beschrijven we verder in meer uitgebreide vorm datgene wat we met dit onderzoek hebben gedaan.

Aanpak
De eerste uitdaging ontstond rond de grote hoeveelheid data binnen dit onderzoek. In totaal had het team te maken met ruwweg 16,7 miljoen akteteksten in XML-formaat, welke op een lokale Kadaster omgeving stonden. Deze(n) zijn ge-upload naar de Azure cloud omgeving en geconverteerd naar het meer bruikbare JSON formaat. Vanuit daar werd het vervolgens verder getransformeerd en geanalyseerd. De akteteksten zijn middels een check op de Nederlandse taal (bestaat het gevonden woord wel/niet in een Nederlands woordenboek) geanalyseerd op de leesbaarheid van de akteteksten. De resultaten van deze analyse zijn in combinatie met een steekproef op een visuele manier getoetst bij de eindgebruikers.
Gebruik van de Microsoft Azure cloudomgeving
Voor dit onderzoek is grootschalig gebruik gemaakt van de Azure cloud omgeving. Een resulterende architectuurplaat is te vinden in Figuur 1.
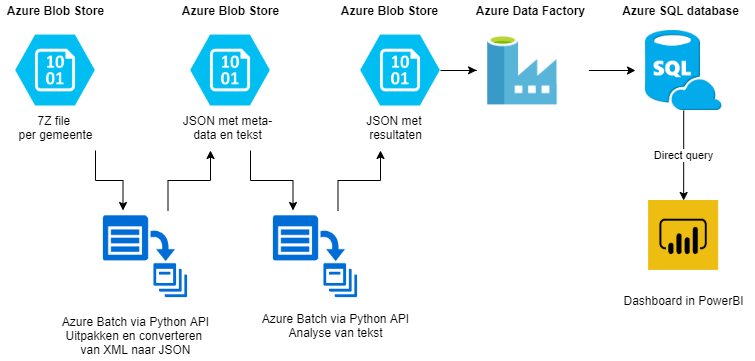
We beginnen met de ruwe data. De aktes zijn gecomprimeerd aangeleverd in 7z fileformaat per vestiging. Deze zijn geplaatst op een Azure Blob Storage in de Azure cloud. Binnen deze gecomprimeerde files staan de akteteksten en metadata in xml formaat. Voor dit onderzoek hebben we gekozen om het formaat van xml naar json om te zetten.
Met behulp van een shellscript wordt het zipbestand opgehaald van de blob, vervolgens uitgepakt, geconverteerd (met behulp van een Python procedure) en terug geplaatst op dezelfde blob. Dit proces werd eerst uitgevoerd op een enkele virtual machine (VM) in de Azure cloud. Dit bleek echter veel tijd te kosten en moest handmatig worden uitgevoerd per zip bestand. De doorlooptijd voor een grote vestiging was een aantal dagen en nam veel opslagruimte in gebruik, tot ver in de honderden gigabytes. Daarvoor is ervoor gekozen dit uitpak proces te parallelliseren en via de cloud dienst “Azure Batch” uit te voeren.
Azure batch is een dienst waarbij taken kunnen worden verdeeld over een rekenpool van meerdere VM’s. De rekenpool wordt automatisch geschaald naar de hoeveelheid resterende taken en zal dus VM’s uitschakelen als deze niet meer nodig zijn. Het uitpakken en converteren van de aktes is omgeschreven naar een set taken voor Azure batch. Hiervoor gebruiken we de Python API. Op deze manier kunnen we in parallel het proces uitvoeren in een automatisch schalende omgeving. Dit heeft de doorlooptijd significant kunnen versnellen.
De Nederlandse taalcheck
In de volgende stap wordt de taalanalyse uitgevoerd op de uitgepakte aktes. Ook hier is er voor een parallel proces in Azure Batch gekozen. De analyse is geschreven in een Python script. In de analyse wordt er gebruik gemaakt van de HunSpell library voor de controle op de Nederlandse taal. Deze spellingcontrole heeft van de Taalunie het “Keurmerk Spelling” gekregen. Hunspell werkt met een Nederlandse woordenlijst en met een lijst met vervoegingen. Op basis daarvan wordt gekeken of een woord een goed Nederlands woord is.
De controle op de Nederlandse taal ziet er schematisch als volgt uit:
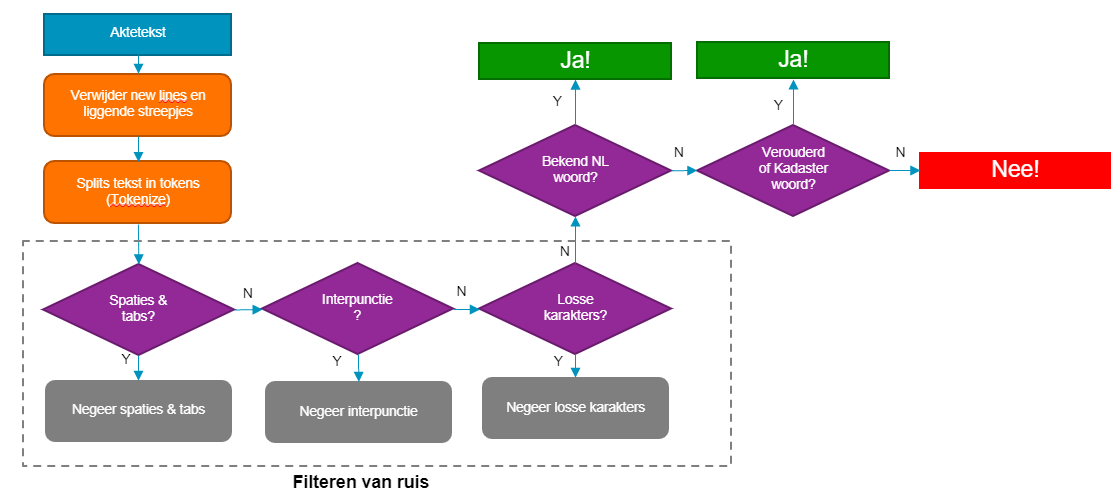
Deze analyse is tot stand gekomen na enkele iteraties, waarbij enkele tussentijdse conclusies waren:
- Kadaster / Notarissen hebben soms een heel expliciet woordgebruik, welke niet altijd door de woordenlijst werden herkend. Dit werd versterkt door het feit dat sommige woorden sinds het begin van de tijdslijn (1950, red.) zijn veranderd in de Nederlandse taal. Zo is het woord komparant bijvoorbeeld veranderd in comparant.
- Voegwoorden (zoals en/of) en afkortingen komen vaak voor in akteteksten. Deze werden in eerste instantie nog niet herkend als Nederlands woord.
Enkele tekortkomingen die in de huidige analyse nog niet worden afgevangen:
- Eigennamen/personalia zijn geen Nederlandse woorden die terug te vinden zijn in de woordenlijst en worden daarom als fout woord geclassificeerd
- Ditzelfde geldt voor objecten als Kadastrale percelen, niet-natuurlijke personen & verwijzingen naar specifieke secties uit het wetboek
We zien echter wel dat de facetten die niet worden afgevangen uit dit lijstje vaak de gegevens zijn die een akte bruikbaar maken voor een domeinexpert. Een akte is pas bruikbaar als een bewaarder of andere expert kan zoeken op deze personalia of betrokken bedrijven.
Samenvattend is er uiteindelijk voor gekozen om eerst de ruis eruit te filteren (zgn. pre-processing). Daarna wordt Hunspell gebruikt om te kijken of een woord voorkomt in de Nederlandse taal. Tot slot wordt er gekeken of het woord voorkomt in een zelf opgestelde woordenlijst. Op basis van de top 400 onbekende woorden (die dus initieel niet herkend werden) is een speciale Kadaster lijst opgesteld. Deze is te vinden in Bijlage B.
Eén van de zaken die ook naar boven kwam is dat er soms relatief veel ruis in een aktetekst voorkwam, zeker in de ‘slechte’ aktes. Dit vertroebelde soms de resultaten. Zo kwam het wel eens voor dat een akte eigenlijk bijna exclusief bestond uit ruis, maar de woorden die over bleven wel herkend werden en door de kleine hoeveelheid totaal aantal woorden als een ‘goede’ akte werd geclassificeerd.
Resultaten tastbaar maken
Om de resultaten over de gehele set aan aktes kwantitatief te maken zijn de volgende twee kwaliteitsindicatoren opgesteld:

Hierbij dienen de grenzen als indicator om iets te kunnen roepen over de kwaliteit van de akten. Om de grenzen te bepalen is gebruik gemaakt van twee methodieken:
- Wanneer we een set aan nieuwe akten door dezelfde analyse halen (en er dus geen OCR aan te pas komt, maar we aktetekst gewoon in de PDF zit) scoren deze gemiddeld respectievelijk 97% op de indicator gevonden woorden en 12% op de indicator ruis.
- Door met de huidige grenzen te kijken naar een steekproef aan akten krijgen we een gevoel over hoe goed en hoe bruikbaar de akte daadwerkelijk is en of de grenzen nog moeten worden aangescherpt.
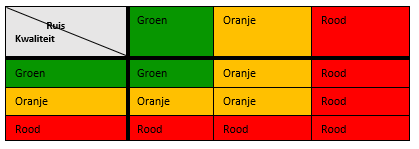
Ruwweg kunnen we over de betekenis van kleuren het volgende zeggen: Groen betekent dat een akte goed leesbaar is. Bij oranje twijfelen we nog en moet er op een case-by-case basis worden besloten of de aktetekst in zijn huidige vorm nog iets kan toevoegen. Van aktes met de kleur rood zien we dat deze vaak volstrekt onleesbaar zijn en geen waarde toevoegen.
Op basis van de twee indicatoren kan er een algemene kwaliteitsindicator worden opgesteld. Zie onderstaande tabel:
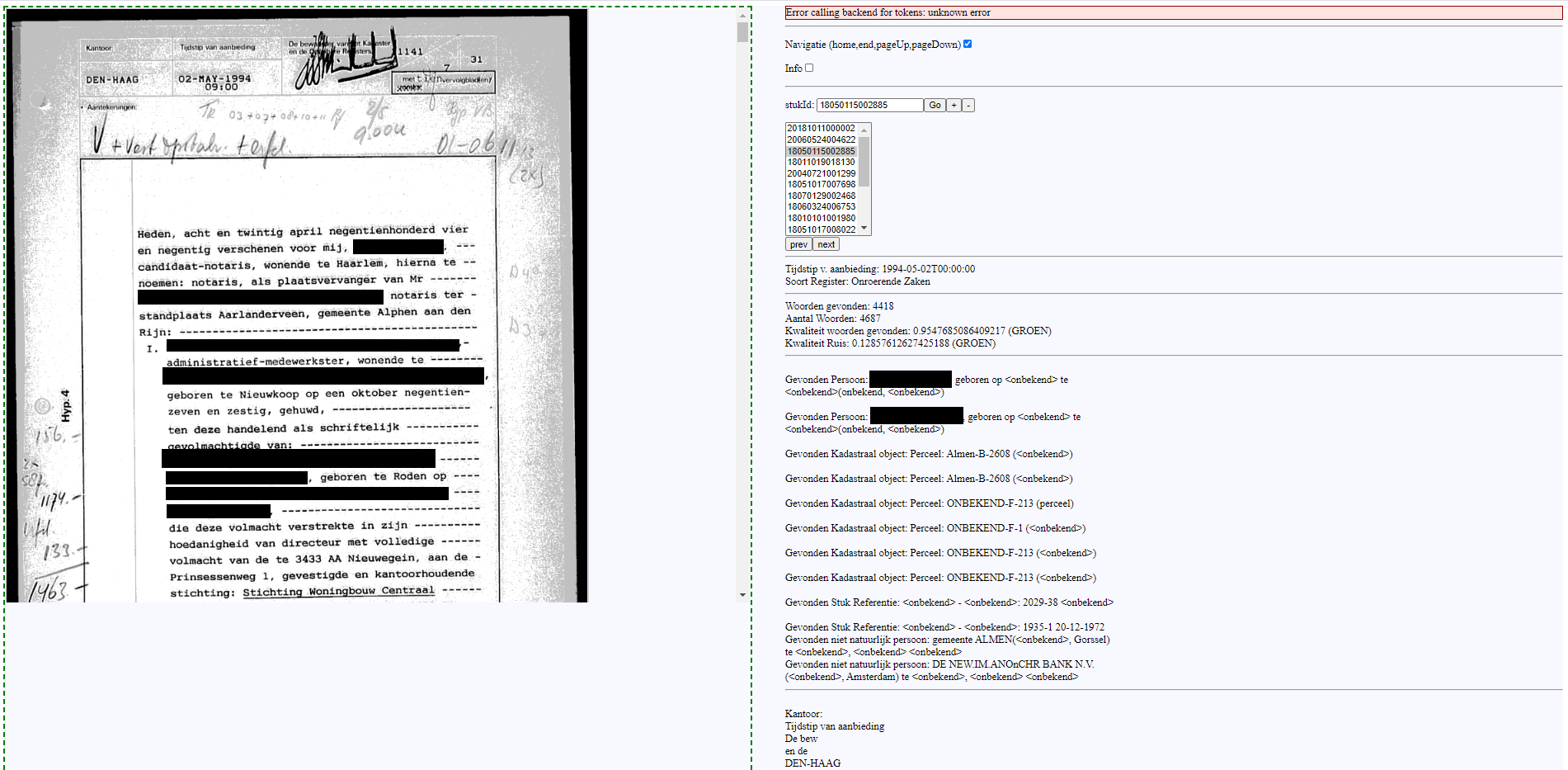
Om de resultaten op steekproefniveau inzichtelijk te maken is gebruik gemaakt van een variant op een user interface die momenteel al bij Kadaster in gebruik is. Daarbij werd ook een bestaand algoritme op de resulterende akteteksten losgelaten om te zien of deze - zonder specifieke training of aanvullingen - de eerste personalia en kadastrale objecten uit de akteteksten kan vinden. Dit is een belangrijk onderdeel gebleken om iets te kunnen roepen over de bruikbaarheid van de resulterende akteteksten voor een domeinexpert. Een screenshot van deze viewer met ge-anonimiseerde akte is te vinden in Figuur 3.
Nieuwe OCR technieken
Voor dit deel heeft eerst een klein vooronderzoek plaatsgevonden waarbij is gekeken welke OCR-technieken momenteel op de markt zijn en hoe goed deze zijn. Om hier inzicht in te krijgen is er intern en extern met diverse personen gesproken en is er deskresearch uitgevoerd. Hieruit kwam naar voren dat de huidige technieken zeer waarschijnlijk een stuk beter zullen zijn dan de technieken die in de periode 2008-2012 gebruikt zijn. Er hebben verschillende ontwikkelingen plaatsgevonden, zoals het gebruik van machine learning, die de kwaliteit hebben verbeterd.
Tijdens dit vooronderzoek is ook gekeken naar de verschillende OCR programma’s die op de markt zijn. De verwachting was dat Tesseract, ABBYY, Google Cloud Vision en Azure Computer Vision het meest veelbelovend en geschikt zouden zijn voor het eventueel opnieuw OCR’en van de aktes. Hierbij is Tesseract de meestgebruikte open source software en zijn ABBYY, Google en Azure betaalde software.
Het proces voor het opnieuw OCR’en gaat als volgt. In de voorbereiding wordt de steekproef binnengehaald en worden de OCR technieken gedefinieerd. Vervolgens vindt er een parallelle verwerking plaats voor het OCR’en van de aktes. Voor elke akte in de steekproef wordt per OCR techniek een API aanroep gedaan. Voorafgaand aan de aanroep wordt voor de Google en Tesseract technieken het ingelezen bestand eerst omgezet naar een JPG bestand, omdat deze technieken niet kunnen werken met een PDF bestand. Tenslotte worden deze resultaten opgeslagen en wordt er de taalanalyse op uitgevoerd zoals eerder beschreven in de aanpak.
Voor alle OCR technieken is ervoor gekozen om zo dicht mogelijk bij de basisinstellingen te blijven. Er is dus een vergelijkbare effort in de programma’s gestoken waardoor deze onderling eerlijk kunnen worden vergeleken. Dit betekent ook dat er nagenoeg geen pre-processing heeft plaats gevonden door het team.
Resultaten
In totaal zijn alle 16,7 miljoen akten verwerkt door onze analyse, maar zijn niet alle resultaten weggeschreven naar de omgeving waarvandaan we de resultaat visueel maakten (middels een Power BI dashboard). Dit heeft er mee te maken dat het overzetten van de individuele resultaten per akte (in .JSON-formaat) naar een SQL Database een onevenredige effort vroeg van het team en de servers die het verwerkten. Er is daarom gekozen om de analyse niet langer door te zetten naar het dashboard na 2 miljoen akten. Voor het restant van de resultaten wordt er dan ook alleen gekeken naar deze twee miljoen akten. De verdeling van deze akten (in bijvoorbeeld jaar en Kadaster vestiging) is wel gelijk gebleven in deze representatieve subset.
Leesbaarheid van akteteksten
Om inzicht te krijgen in de kwaliteit van de akteteksten is gebruik gemaakt van drie indicatoren; indicator gevonden woorden, indicator ruis en de gecombineerde indicator van deze twee (zie “Aanpak”). In onderstaande tabel wordt de verdeling voor de eerste twee indicatoren getoond.
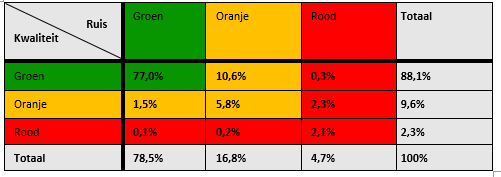
In deze tabel is te zien dat het merendeel van de akteteksten, ongeveer 1,5 miljoen, het label groen heeft gekregen en dus wordt beschouwd als goede akteteksten. Ongeveer 11% van de akteteksten heeft groen op de ruisindicator maar oranje op de indicator voor gevonden woorden. Dit is de op één na grootste groep. Dit betekent dat tussen de 70% en 90% van de tokens werd herkend als Nederlandse taal. De gemiddelde ratio voor de gevonden woorden is 91% wat ook laat zien dat voor een groot deel van de akteteksten veel woorden werden herkend. Tot slot wordt slechts ongeveer 5% van de akteteksten bestempeld als rood en dus als slecht beschouwd.
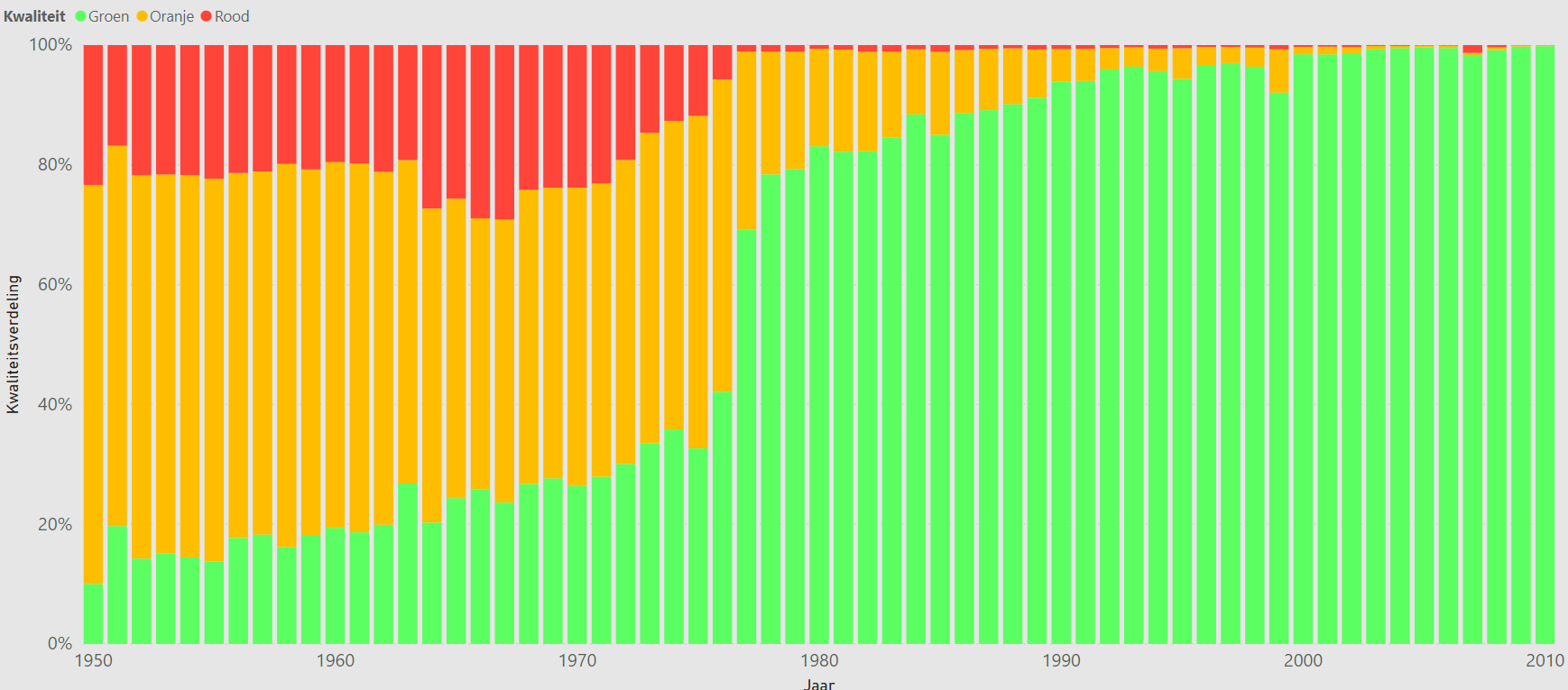
Er is ook gekeken of er een relatie is tussen de kwaliteit en het tijdstip van aanbieding. Het is te verwachten dat een oudere akte vaak een slechtere scan heeft en daardoor lastiger is om voor een OCR techniek te interpreteren. De resultaten daarvan zijn te vinden in Figuur 4.
Bruikbaarheid van akteteksten
Door het bekijken van verschillende aktes middels de getoonde user interface kwamen we tot de volgende inzichten per categorie:
- Groene akteteksten; deze akteteksten zijn over het algemeen goed leesbaar. Het enige waar de OCR vaak niet goed mee om kon gaan is de koptekst en eventuele aantekeningen door de medewerker. Deze zijn vaak handgeschreven. De akte-ai parser weet bij deze akteteksten vaak ook verschillende entiteiten te herkennen. De kanttekening is wel dat de parser vaak niet alles weet te vinden en dat de gevonden entiteiten ook niet altijd helemaal correct zijn.
- Oranje akteteksten; deze akteteksten zijn over het algemeen minder goed leesbaar en de akte-ai parser kan hier ook minder vaak entiteiten in vinden. Afhankelijk van de use case zouden deze nog gebruikt kunnen worden ter ondersteuning. Hierbij is het goed om deze groep nog verder te onderzoeken.
- Rode akteteksten; dit zijn slechte akteteksten die niet bruikbaar zijn. Vaak zijn deze akteteksten niet leesbaar en kan je er dus ook geen essentialia in vinden. Echter is dit ook een indicatie dat de originele scan mogelijk ook van slechte kwaliteit is, iets wat klachten kan veroorzaken wanneer deze akte wordt geleverd aan een klant. De kennis van de kwaliteit van een dergelijke akte kan een signaal zijn dat er even een mens naar het product moet kijken voordat het wordt uitgeleverd.
Over het algemeen kan er worden geconcludeerd dat de kwaliteitsscore vooral een goede indicatie is voor de leesbaarheid van de tekst.
Wel is er nog een kanttekening te plaatsen over de bruikbaarheid van akten, ook als de leesbaarheid zeer hoog is. Vaak zit de waarde in een akte in het vinden van de meest belangrijke feiten en essentialia uit de gegeven aktetekst. In de praktijk komt het nog wel eens voor dat juist deze essentialia door de notaris werd benadrukt door bijvoorbeeld de eigennamen te onderstrepen. We zien in de resultaten terug dat dit soms precies een stuk is waar de OCR-techniek over struikelde, ook als de rest van de akte van zeer hoge kwaliteit is. Daarom kan er met een hoge kwaliteit voor een akte nog niet per se een foutloos en volledig bruikbare akte worden geconcludeerd. Een voorbeeld van een akte met een dergelijke nadruk op essentialia vind je hieronder in Figuur 5 (geanonimiseerd).

Nieuwe OCR Technieken
Na voorgaande analyse zien we dat de eerder gebruikte OCR techniek toch best wat moeite had met een flink aantal akten. Uiteindelijk zijn we vooral benieuwd of de nieuwe OCR technieken tot betere resultaten leiden door te kijken hoe goed ze scoren op aktes die groen/oranje/rood hadden gescoord bij de analyse van het eerdere deel. Daardoor vergelijken we de akten ten opzichte van de eerdere resultaten. In Figuren 6 tot en met 8 vinden we de resultaten voor nieuwe technieken wanneer we deze vergelijken met aktes uit de kwaliteitsgroepen groen, oranje en rood respectievelijk.
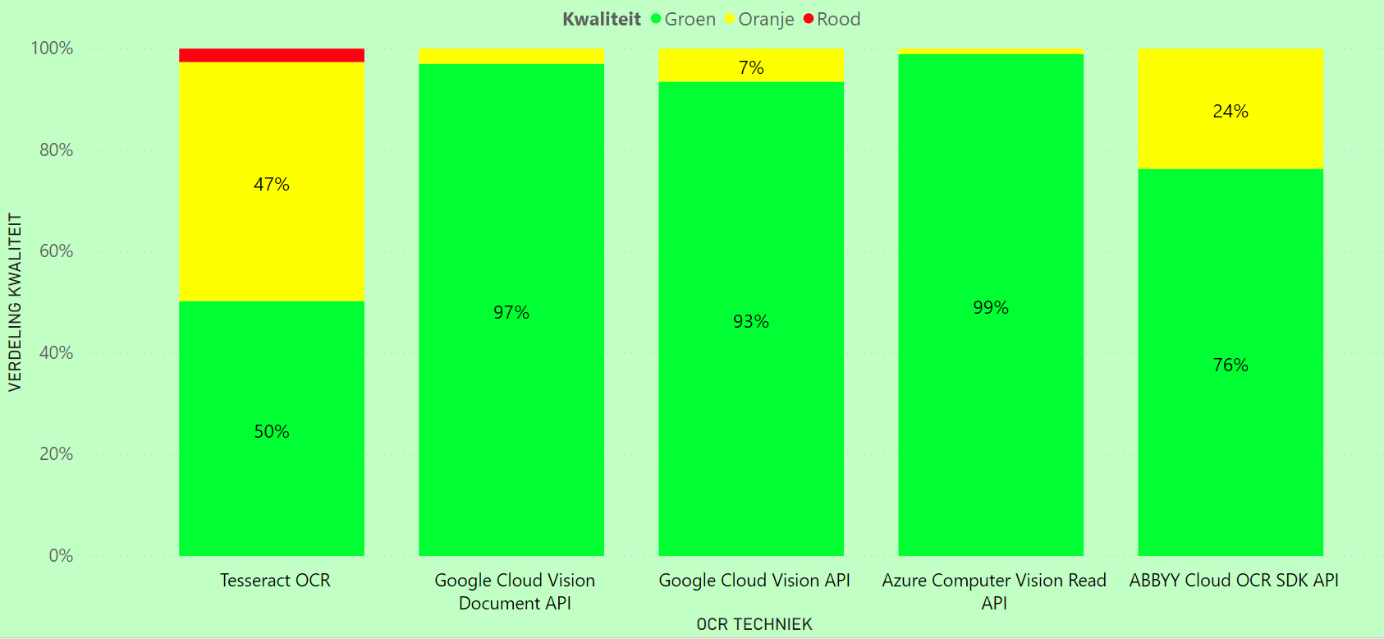
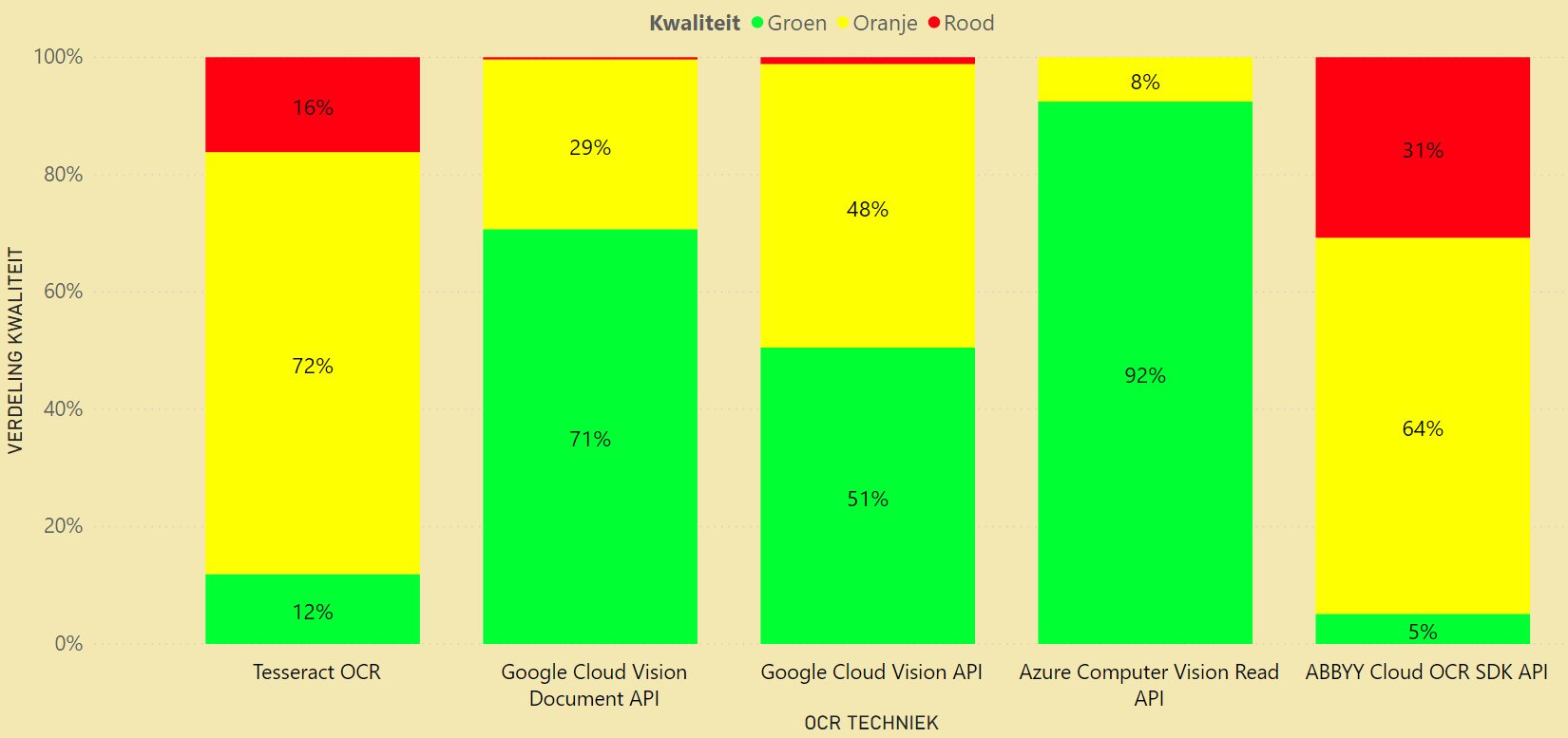
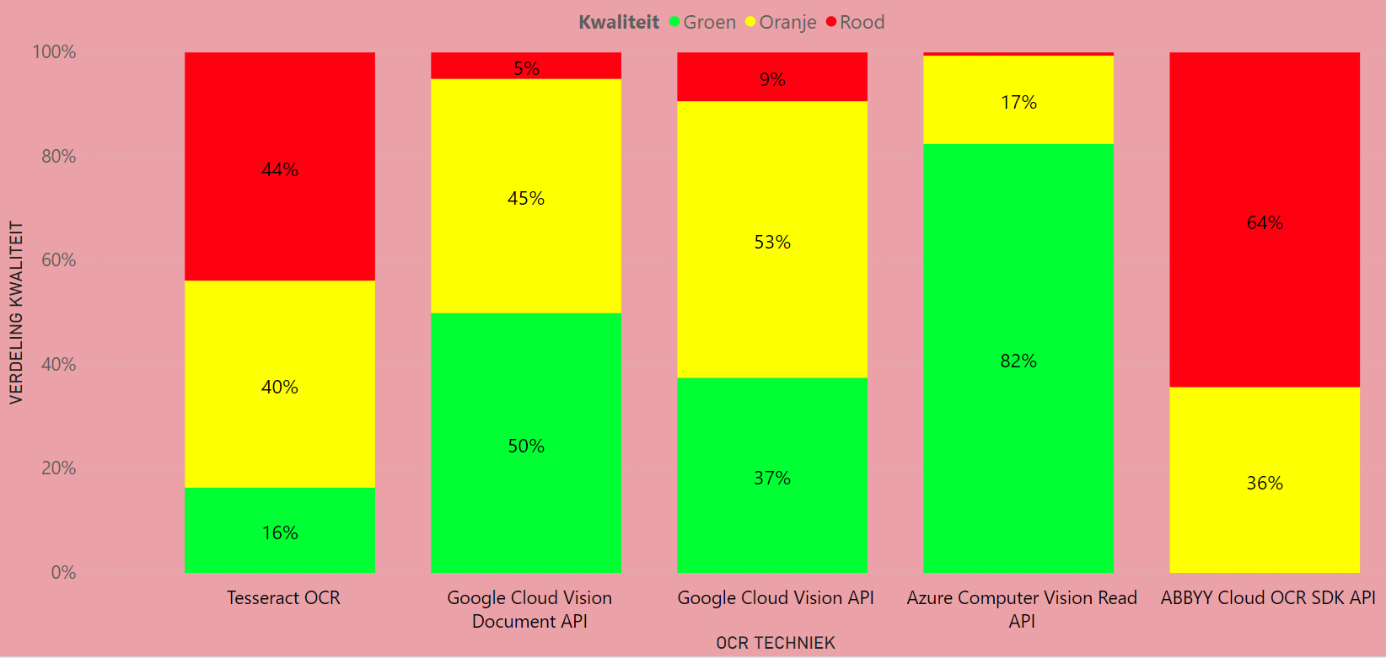
De figuren tonen aan dat Azure en Google voor deze aktes ook overwegend groen scoren. Dit betekent dat zij het voor deze aktes niet slechter doen en vergelijkbare resultaten krijgen. ABBYY en Tesseract scoren daarentegen regelmatig minder dan de oude technieken. Onderstaande figuur toont de resultaten voor de oranje akteteksten. Hierin is te zien dat Azure voor deze aktes een grote kwaliteitssprong kan realiseren. Slechts voor 8% wordt geen verbetering gerealiseerd in kwaliteitsscore. Na Azure komt de Google Document API en vervolgens de algemene Google API. Deze scoren allebei overwegend beter dan de oude akteteksten. Tesseract en ABBYY scoren daarentegen over het algemeen vergelijkbaar of slechter dan de oude akteteksten.
De verschillende akteteksten laten daarnaast zien dat Google en Azure ook daadwerkelijk de leesbaarheid en bruikbaarheid kunnen verbeteren. We hebben verschillende resultanten bekeken en vergeleken en Google en Azure herkennen meer woorden correct. Ook hebben zij bijvoorbeeld minder moeite met onderstreepte woorden waardoor zij ook vaker de essentialia correct uit de akte halen.
Ook in de rode akteteksten weten Azure en Google een grote kwaliteitssprong te realiseren en scoort Azure weer het beste. Tesseract en ABBYY weten hier ook iets beter te scoren dan de oude akteteksten maar scoren beduidend minder dan Google en Azure. Azure scoort voor slechts 1% van de aktes rood. Deze aktes zijn bekeken en hieruit werd duidelijk dat de scans van dermate slechte kwaliteit zijn dat deze voor een persoon ook lastig tot niet te lezen zijn. Hetzelfde geldt voor de rode aktes van Google en een deel van de oranje aktes van Azure. De mindere scores op deze aktes liggen dus niet aan de kwaliteit van de OCR maar eerder aan de kwaliteit van de scan.
Wanneer we naar de bruikbaarheid kijken van de akten wanneer deze door nieuwe OCR-technieken zijn gehaald dan zien we ook daar verbeteringen in de nieuwe OCR-technieken. Allereerst zijn er überhaupt meer woorden die gevonden worden met de technieken, wat automatisch een grotere slagingskans op het juist herkennen van de relevante informatie betekent, maar ook hebben de nieuwe OCR-technieken op het eerste oog minder moeite met de specifieke benadrukking van essentialia zoals beschreven in het kopje ‘bruikbaarheid’ bij het eerdere van dit onderzoek. We concluderen dan ook dat nieuwe OCR-technieken ook voor de bruikbaarheid van akten een positieve push kan geven.