
AI-assistent voor metadata generatie
Het opstellen van metadata wordt soms als tijdrovend en complex ervaren. Om te onderzoeken hoe dit proces eenvoudiger en minder arbeidsintensief kan worden gemaakt, heeft het Kadaster gekeken naar mogelijkheden om het complexe proces van metadata-generatie te versimpelen met behulp van moderne AI-technologie. Een belangrijk doel hierbij is dat de kwaliteit van de metadata verbetert, waardoor data beter vindbaar wordt en het hergebruik ervan toeneemt. De resultaten van het onderzoek zijn samengebracht in een vernieuwende demo-applicatie. Deze applicatie ondersteunt het automatisch aanmaken van metadata op basis van de echte data en documentatie en biedt hulp via een interactieve chatbot.
Wat is metadata?
Simpel gezegd: metadata zijn gegevens over gegevens. Wanneer je bijvoorbeeld een digitale kaart met informatie over locaties gebruikt, geeft metadata heldere informatie over wat het is, waar het vandaan komt, wanneer het is verzameld en hoe je het kunt gebruiken. Voor overheden, bedrijven en burgers is betrouwbare metadata onmisbaar om digitale informatie vindbaar, deelbaar en begrijpelijk te maken. Voor veel organisaties, waaronder het Kadaster, is het vaak verplicht om metadata te registreren. Nationale en Europese wetgeving, zoals de Wet open overheid (Woo) en richtlijnen als INSPIRE, geven aan dat overheden hun datasets moeten voorzien van gestandaardiseerde metadata. Het zorgvuldig vastleggen van metadata draagt dus niet alleen bij aan een betrouwbare gegevenshuishouding, maar maakt het delen en hergebruiken van data ook makkelijker voor iedereen.
Hoe werkt het?
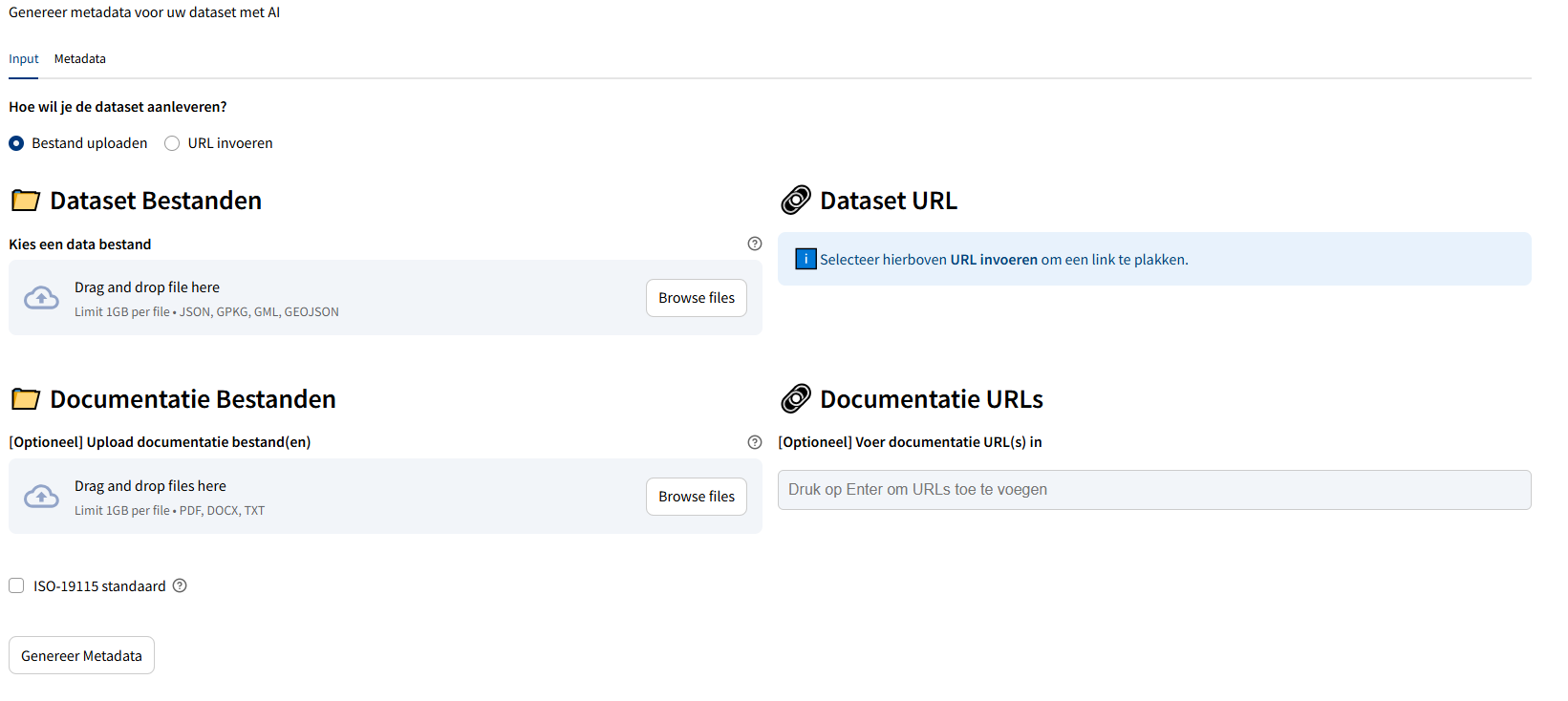
De applicatie benut artificiële intelligentie (AI) om metadata te genereren volgens standaarden, zoals ISO 19115 waar nodig aangevuld met Europese richtlijnen zoals INSPIRE. Hoewel uitbreiding naar andere formaten en standaarden nog ontbreekt, zijn de mogelijkheden veelbelovend (bijvoorbeeld DCAT). Gebruikers leveren eerst beschikbare informatie aan, zoals een databestand. Denk hierbij bijvoorbeeld aan een GeoPackage, JSON of GML-bestand maar een beschrijving van een datamodel kan ook. Vervolgens kan er eventuele extra beschikbaar documentatie over de data aangeleverd worden. Daarna kan het systeem snel en gestructureerd aan de slag om zoveel mogelijk velden te generen zoals voorgeschreven in de ISO standaard.
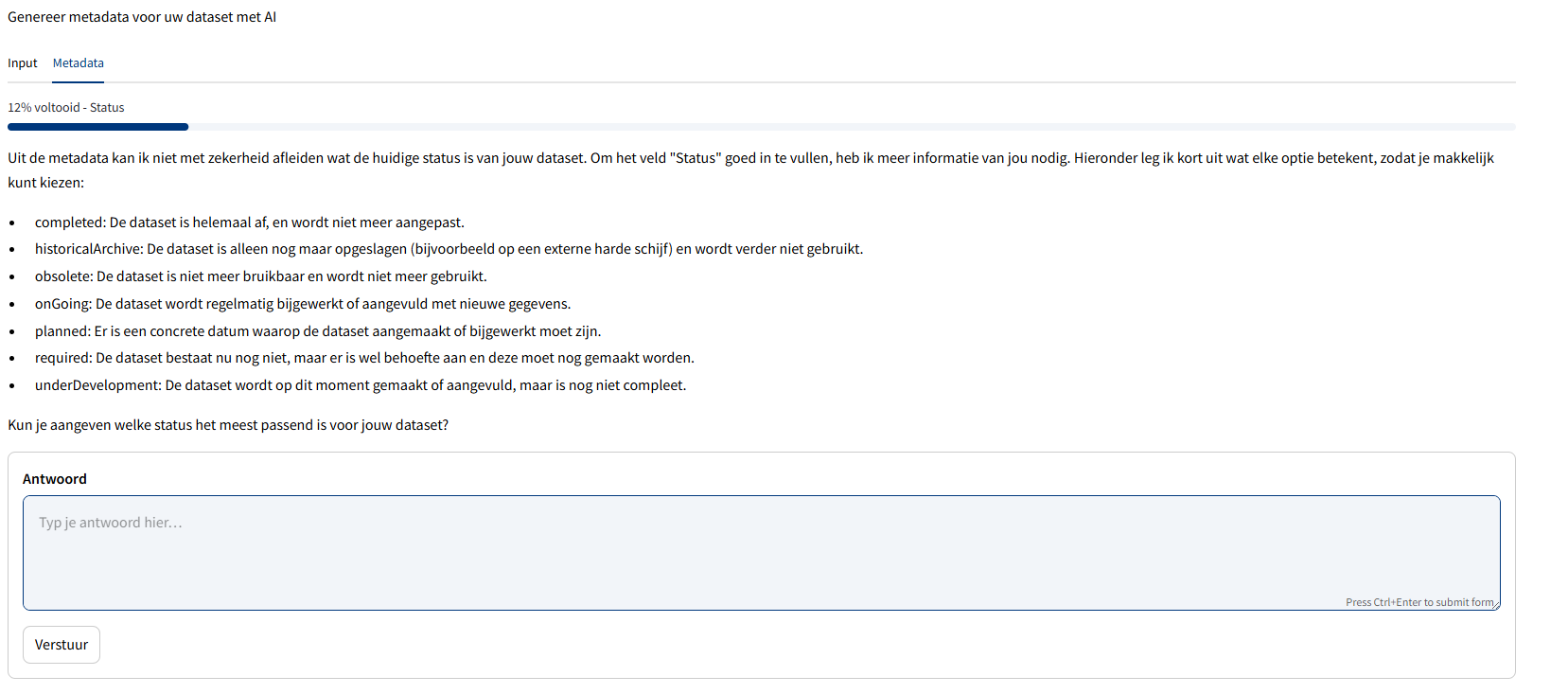
Voor aanvullende informatie schakelt de applicatie over op een interactieve chatbot, die op een toegankelijke manier in gesprek gaat met de gebruiker. Complexere vragen worden waar nodig toegelicht en gebruikers kunnen wedervragen stellen voor verdere verduidelijking of versimpeling. Zo wordt de gebruiker stap voor stap door het proces geleid en ontstaat er complete, consistente en hoogwaardige metadata. Belangrijk uitgangspunt bij dit onderzoek is dat de gebruiker altijd verantwoordelijk blijft voor het controleren, aanvullen en uiteindelijk publiceren van de metadata, zodat de kwaliteit gewaarborgd is.
Zodra de metadata is gegenereerd, gevalideerd en waar nodig gecorrigeerd, kunnen gebruikers deze publiceren, bijvoorbeeld op het Nationaal Georegister (NGR). De oplossing is zo ingericht dat het op termijn wellicht ook voor andere standaarden, toepassingen en processen ingezet kan worden. Zo is er bijvoorbeeld al een vooronderzoek gedaan naar de mogelijkheden om metadata te genereren volgens de DCAT standaard.
Een kijkje onder de motorkap
De metadata wordt gegenereerd op basis van data en optionele documentatie. Vanuit de data wordt een representatieve set rijen geselecteerd, evenals het referentiesysteem en de omgrenzende rechthoek (data-metadata). Indien documentatie beschikbaar is, worden suggesties voor verschillende velden gegenereerd met behulp van een Azure OpenAI LLM (documentatie-metadata). Er wordt een afhankelijkheidsgraaf opgesteld van velden die van elkaar afhankelijk zijn, zodat bijvoorbeeld de datum en tijd van gegevensverzameling gestructureerd en consistent verwerkt worden. Per veld wordt gecontroleerd of het vanuit beschikbare data-metadata of documentatie-metadata kan worden ingevuld. Bij onduidelijkheden wordt de gebruiker bevraagd via een AI-model. Dit interactieve vraag-en-antwoordproces zorgt ervoor dat de AI suggesties doet en de gebruiker toelichting of aanvullende informatie kan verstrekken. Het schema van de output (zoals ISO) wordt afgedwongen door PydanticAI, een bibliotheek die validatie en structurering verzorgt om fouten te minimaliseren en de kwaliteit te waarborgen. Zodra alle velden zijn ingevuld, kan de volledige set metadata als XML-bestand worden gedownload. Dit bestand kan vervolgens worden gevalideerd, gecorrigeerd en gepubliceerd op platforms zoals het Nationaal Georegister of andere locaties.
Meer weten?
Het Data Science Team en PDOK zijn enthousiast over wat deze demo-applicatie laat zien: het is een krachtig hulpmiddel dat het werk van metadata-verantwoordelijken lichter maakt. PDOK onderzoekt nu of en hoe de resultaten in de praktijk kunnen worden ingezet. Meer informatie of eens van gedachten wisselen? Neem gerust contact op via datascience@kadaster.nl of ppb.pdok@kadaster.nl.