
Chatbot Kaatje
De afgelopen periode heeft Generatieve AI een vlucht genomen en zijn er bij het Data Science Team verschillende verzoeken gekomen voor de ontwikkeling van een chatbot. Om de uniformiteit en standaardisatie te verhogen is er middels een technische verkenning onderzocht of er een generieke chatbot ontwikkeld kan worden die verschillende use cases kan ondersteunen. Binnen deze verkenning is een prototype van een generieke chatbot opgeleverd: Kaatje.
Werking van Kaatje
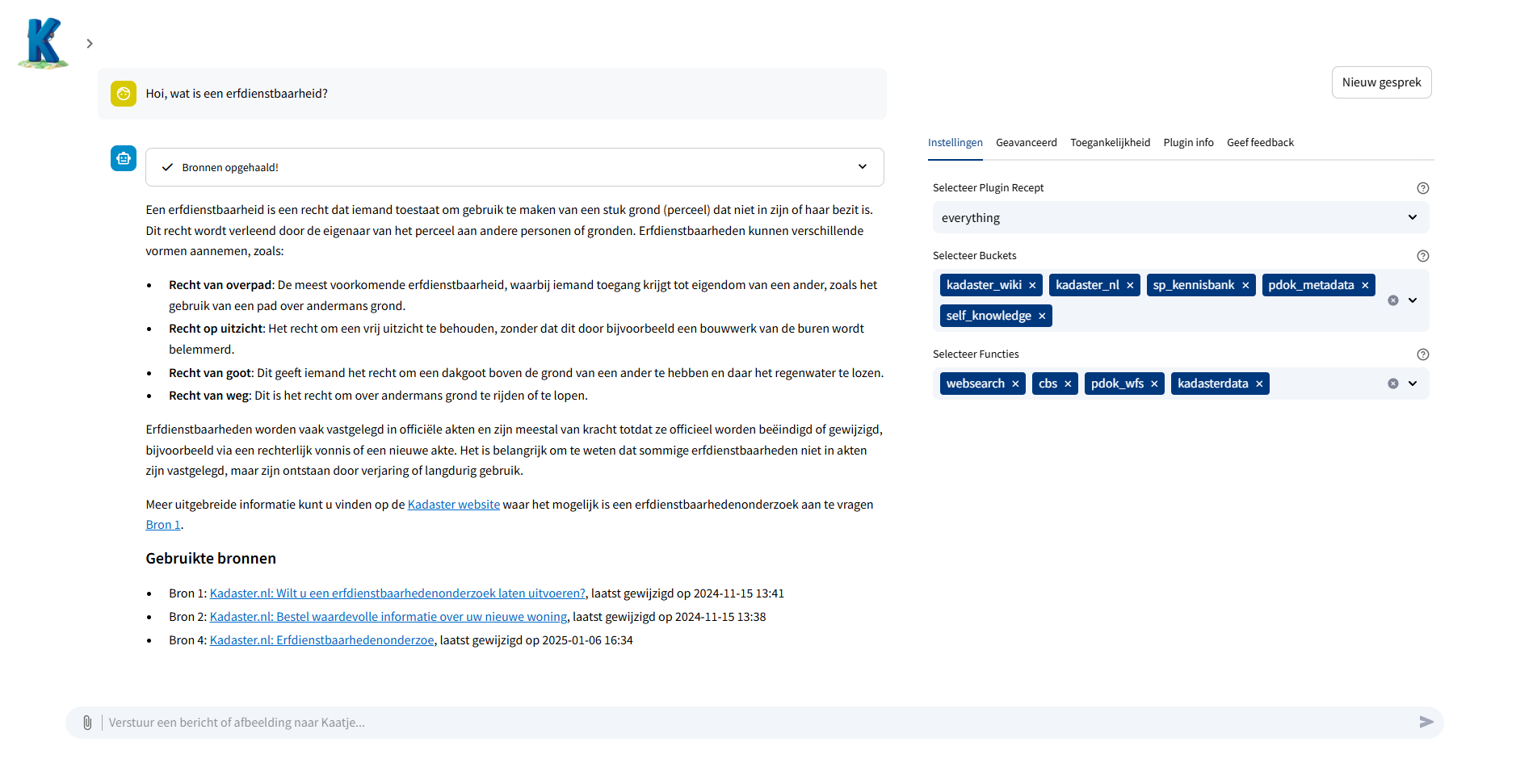
Kaatje werkt op basis van taalmodellen. Door een generatief taalmodel te gebruiken kan een chatbot goed praten over allerlei verschillende onderwerpen. Deze taalmodellen zijn echter niet waarheidsgetrouw, ze genereren voornamelijk antwoorden die taalkundig goed klinken. Zo kan het zijn dat er antwoorden terugkomen die weliswaar goed klinken, maar feitelijk onjuist zijn. Er zijn verschillende manieren om wél een chatbot op basis van een taalmodel te ontwerpen, door het gebruik van externe bronnen om antwoorden op te baseren (het zogenoemde “gronden”). Hierdoor zijn er minder foutieve antwoorden en kun je een chatbot inzetten voor verschillende use cases.
Het gronden van antwoorden
RAG
Onze aanpak voor het gronden van het taalmodel met Kadasterdata is gebaseerd op Retrieval Augmented Generation (RAG). Dit komt erop neer dat brondocumenten met behulp van een “embedding model” worden omgezet naar hun semantische betekenis (embedding vector). Als van een gestelde vraag ook de embedding vector wordt berekend, kan het meest relevante document worden gevonden door de documenten met de hoogste similarity te vinden.
Hoewel dit al aardig werkt, hebben we nog additionele technieken toegevoegd om het vinden van de relevante brondocumenten nog verder te verbeteren:
- Hybrid Search: Hierbij combineren we zowel vector similarity search als traditionele keyword search (bijvoorbeeld BM25).
- Reranking: Om de meest relevante documenten te identificeren, wordt er een extra reranking stap uitgevoerd met een tool als de Cohere reranker.

Het gebruik van RAG met de extra toevoegingen stelt Kaatje in staat om vragen goed op basis van bronnen te beantwoorden.
Functies
Naast het ophalen van relevante documenten middels RAG ondersteunen we een andere functionaliteit: het aanroepen van gereedschappen of tools (functies), oftewel ‘function calling’. In principe kan dit gereedschap van alles zijn, zolang het in code is uit te drukken. In de praktijk betekent dit meestal het doorzoeken van het internet, of gebruik maken van een specifieke API. Een taalmodel kan bijvoorbeeld nooit uit zichzelf het huidige weer weten, maar door gebruik te maken van een Weer-API kan er real-time informatie opgehaald worden. Zodoende kan Kaatje toch communiceren over informatie die niet in haar trainingsdata voorkomt, of heel recent is.
Voor Kaatje hebben we als eerste stap toegevoegd dat er een toolselectie gedaan kan worden. Op basis van de vraag wordt ingeschat of het antwoord direct te beantwoorden is, informatie daarvoor in een brondocument kan worden gevonden, of dat er een extra tool nodig is. We hebben de volgende functies daarvoor als test toegevoegd:
- Zoeken op het web: Met behulp van de Bing API haalt Kaatje actuele informatie op voor onderwerpen als wetgeving of marktontwikkelingen.
- Kadasterdata: Voor vastgoed- en geografische data worden specifieke tools ingezet, die op basis van de gebruikersvraag de relevante data uit de Kadaster Knowledge Graph (KKG) via de KKG GraphQL API of Publieke Dienstverlening Op de Kaart (PDOK) datasets ophalen via de PDOK APIs.
- CBS data: Voor statistische en demografische gegevens wordt er data opgevraagd via de CBS API.
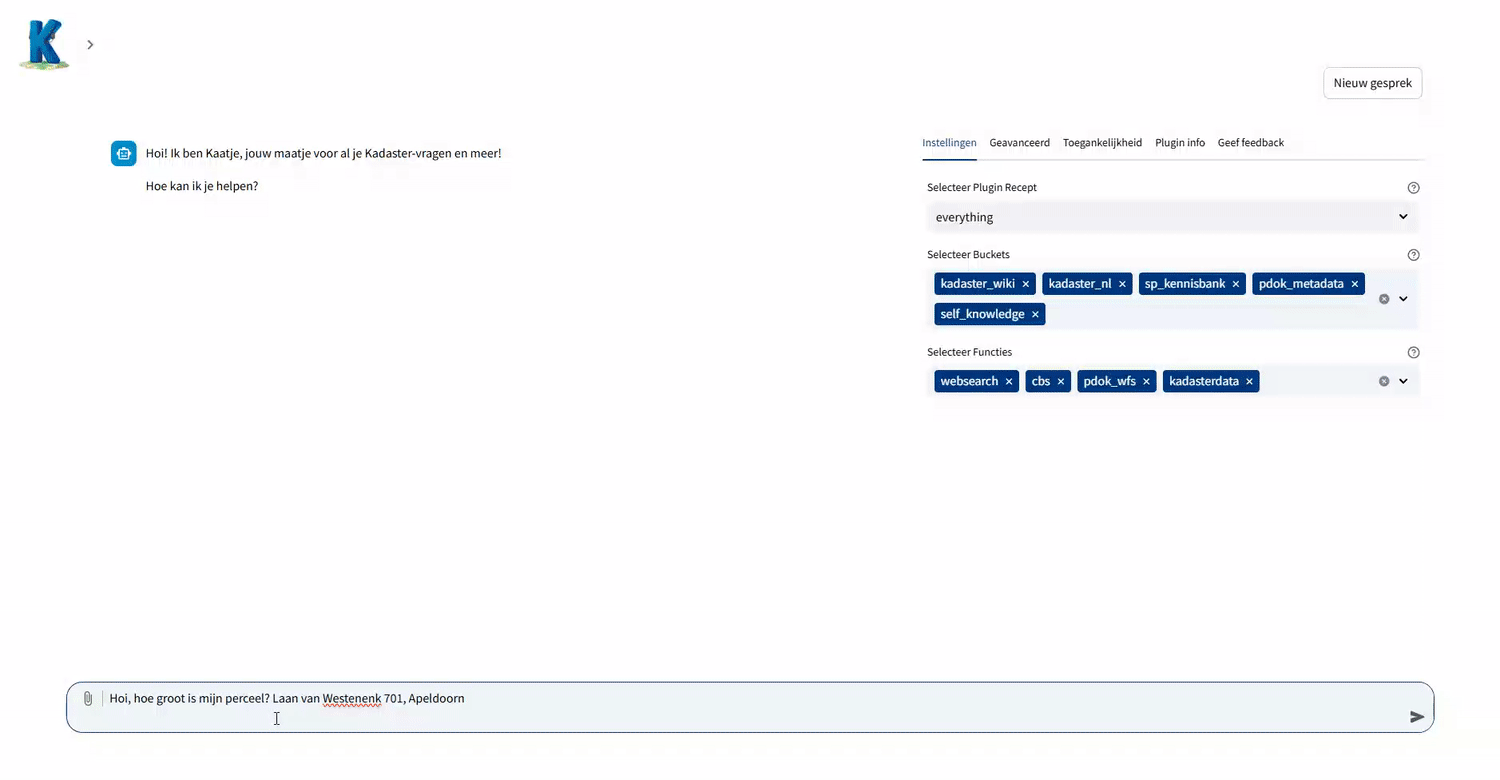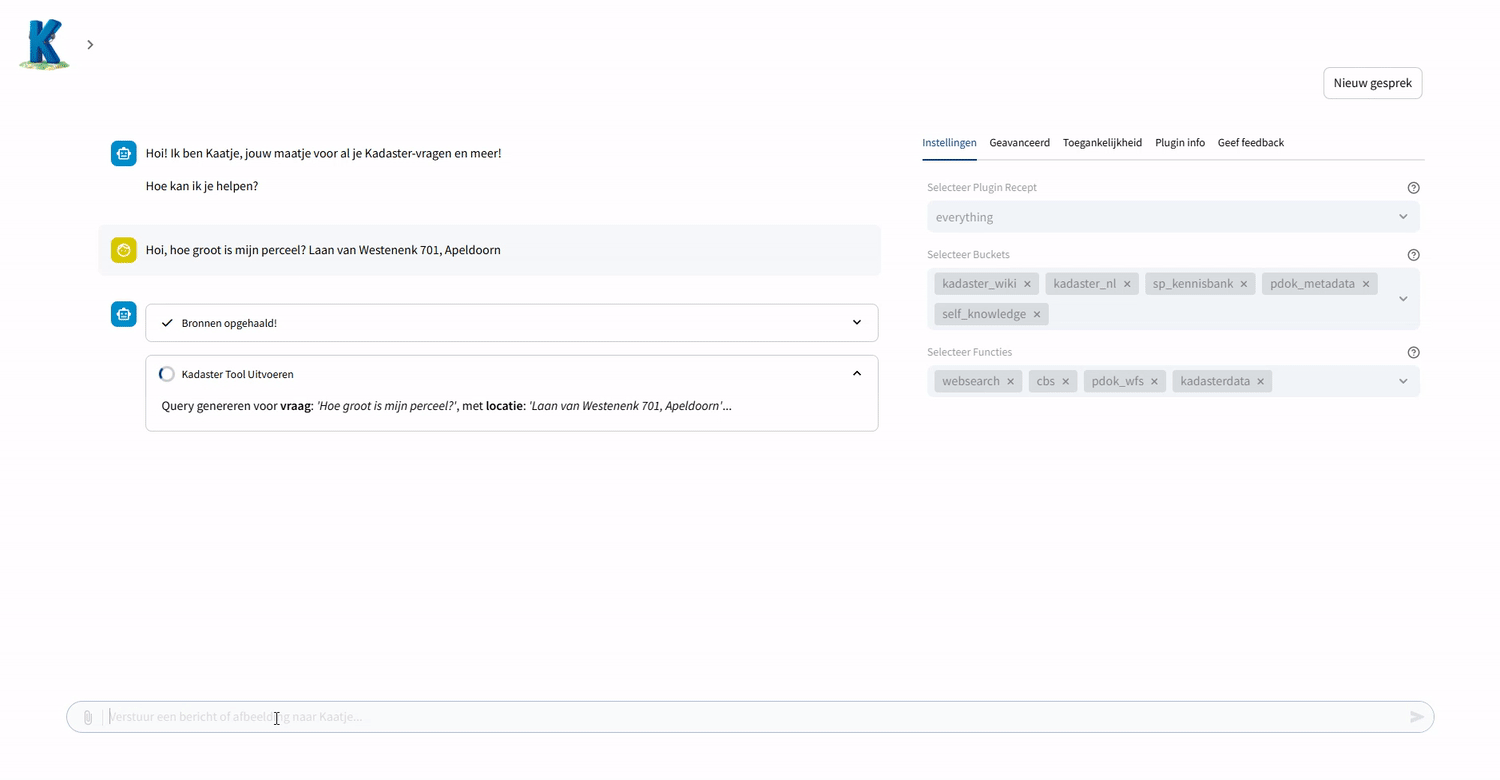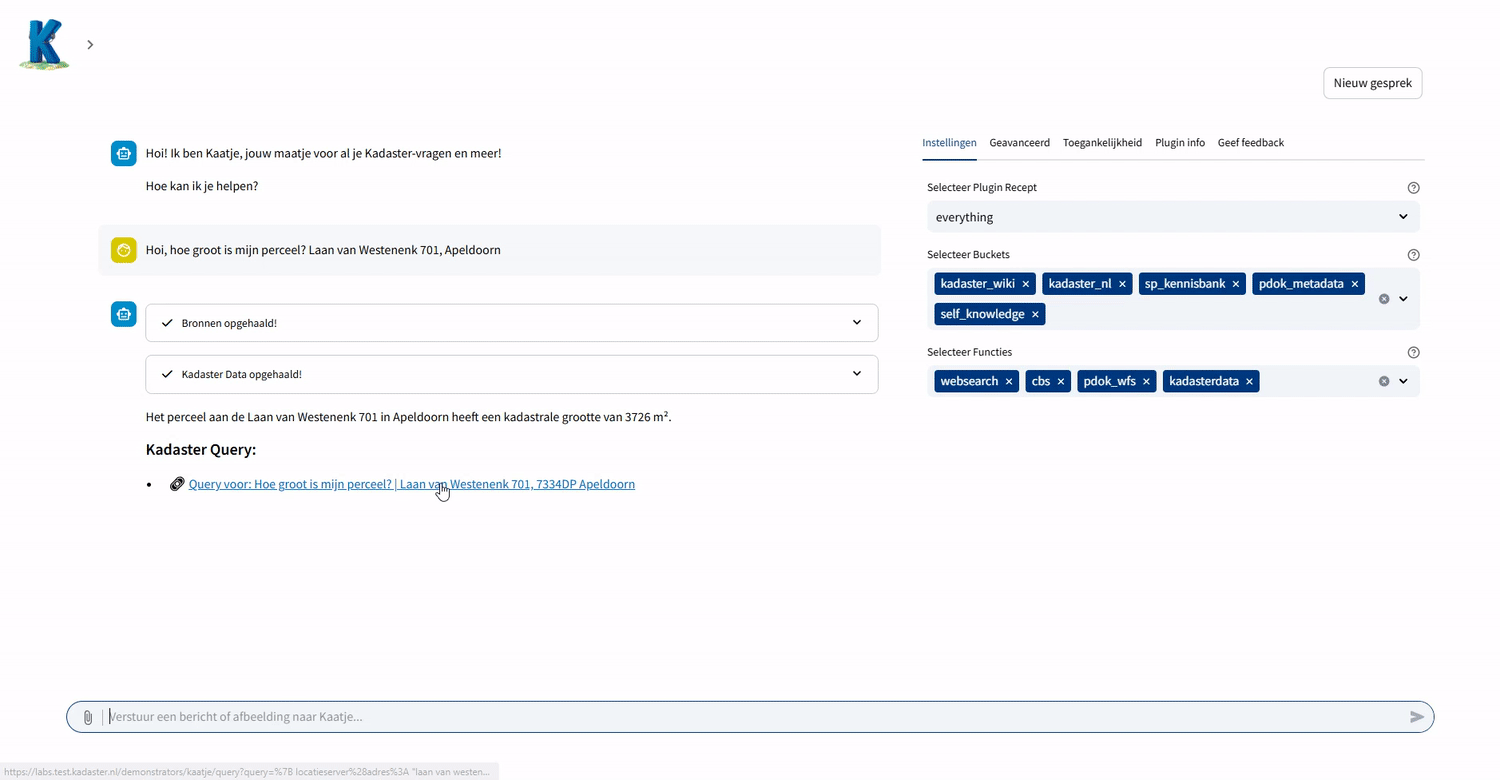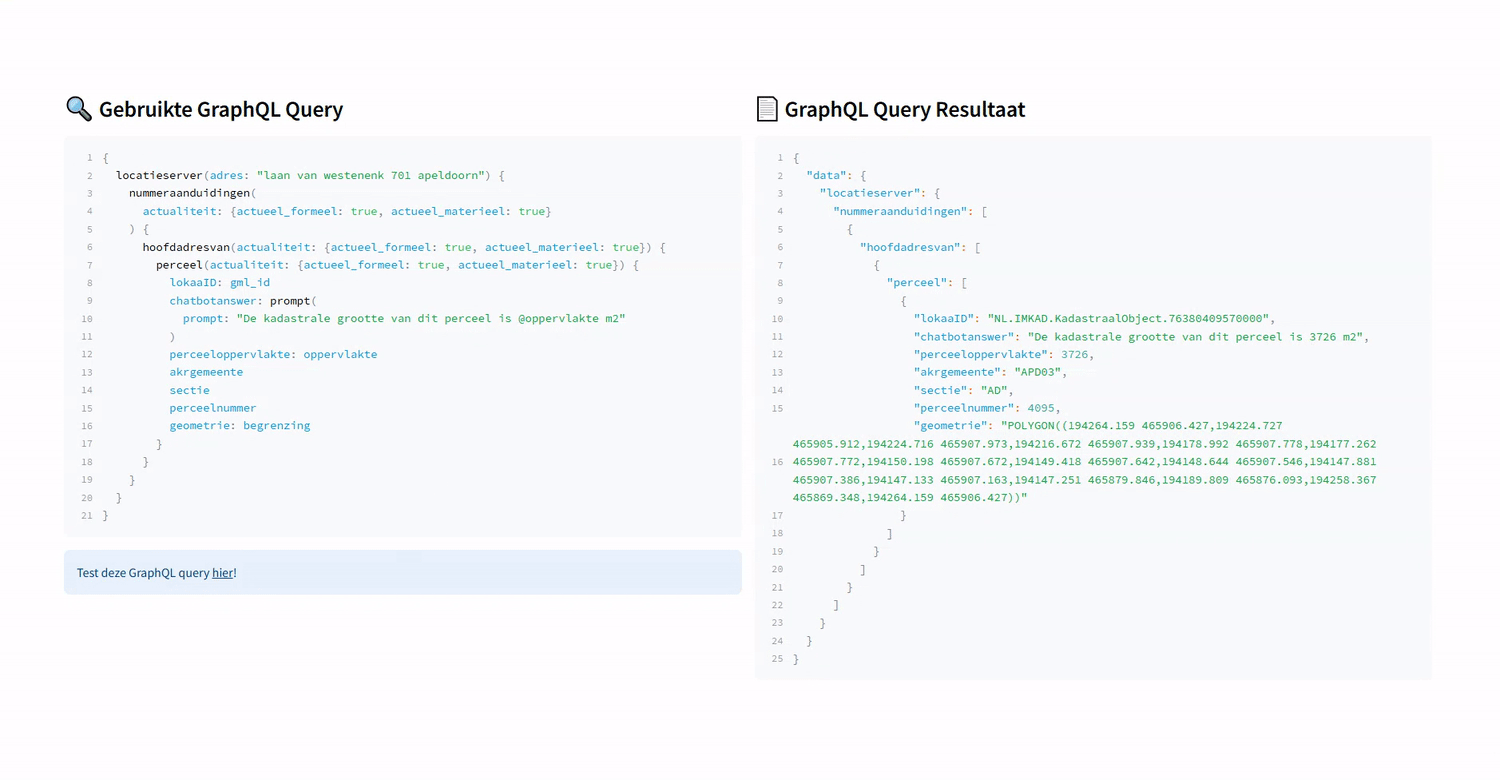
Ondersteunen van verschillende use cases
Met RAG en functies kunnen antwoorden gegrond worden en door verschillende documenten en functies toe te voegen kan de chatbot al op een breed scala aan vragen antwoord geven. Om verschillende use cases verder te kunnen ondersteunen maken we gebruik van twee concepten: buckets en recepten.
Buckets en recepten
Kaatje beschikt over verschillende “buckets”, afzonderlijk bevraagbare sets aan data. Deze sets zijn embedding vectors (die als bron voor RAG gebruikt worden) waarin tekstfragmenten uit diverse brondocumenten worden opgeslagen. Dit kan bijvoorbeeld de Kadaster-website of de interne Kadaster-Wiki en -Kennisbank zijn. Door autorisaties toe te passen op de buckets en functies kunnen we er ook voor zorgen dat alleen specifieke groepen toegang hebben tot informatiebronnen.
Je kunt zelf ook kiezen welke bronnen (waar je recht toe hebt) wilt raadplegen en de voorkeursselectie opslaan als een “recept”. Dit ondersteunt verder het naast elkaar laten bestaan van verschillende toepassingen, met mogelijk verschillende databronnen.
Verdere ontwikkeling
Met Kaatje hebben we geprobeerd een generieke onderlaag te ontwerpen, waarop verschillende toepassingen ontwikkeld kunnen worden. Zoals hiervoor getoond kan Kaatje ingezet worden als vraagbaak voor verschillende databronnen, of als verstrekker van (geo-)informatie met de verschillende functies. Hoewel de demoversie geen kaartmateriaal kan genereren, is het wel in staat om rudimentaire vragen over kaarten te beantwoorden. Het laat mooi een breed scala aan mogelijke toepassingen zien.
Een mogelijke use case voor Kaatje is het beantwoorden van eerder gestelde vragen van (interne) support teams over domein-specifieke vragen of het bevragen van werkinstructies. Ook bekijken we of Chatbot Loki hierop kan landen, of dat de twee chatbots naast elkaar blijven bestaan.

Meer weten over de onderliggende techniek van Kaatje? Op Over ons kun je lezen hoe je contact kunt opnemen.