Solution Architecture
Uiteindelijk streven wij ernaar onze data zo laagdrempelig en integraal mogelijk beschikbaar te stellen. Dat gaat uiteraard niet vanzelf. In zijn totaliteit onderkennen wij een Solution Architecture voor de totale ontsluiting. Deze zullen we hier toelichten.
Architectuur
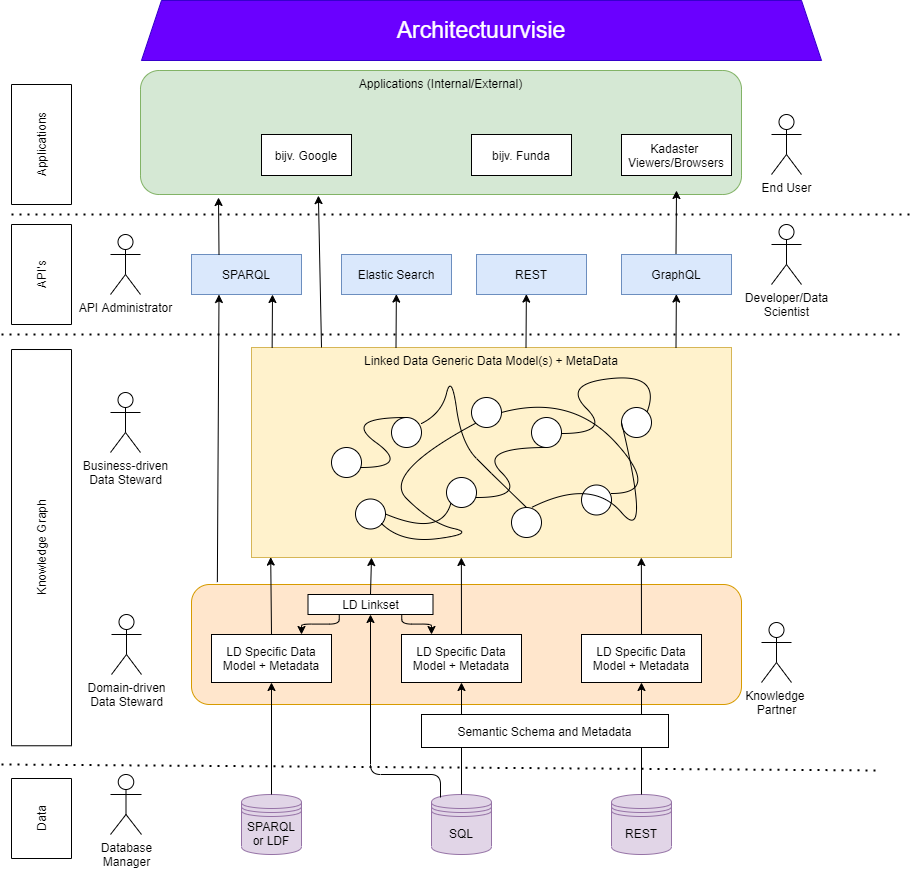
In de essentie begint onze gedachte bij de data. Hierbij doen we doelbewust geen uitspraken over de specifieke databronnen. De aanpak die wij schetsen is generiek en zal moeten werken voor verschillende soorten data en databronnen. Databronnen benaderbaar met SQL, Linked Data en REST (vanuit de bron) noemen we hier expliciet. Op deze typen bronnen hebben wij eerder succesvol linked data ontsloten. Wij ontsluiten deze bronnen middels GraphQL. (zie ook GraphQL-ETL)
Vanuit deze bronnen maken/hebben wij een Linked Data specifiek model (zie ook Modelling) waarheen wij de brondata omzetten. Deze omzetting doen wij met een component wat wij de Enhancer noemen. Het resulterende datamodel representeert vaak een vertaling die dicht op het oorspronkelijke datamodel van de bron ligt en is derhalve herkenbaar voor de dataset-eigenaar. Deze resulterende LD – registraties zijn vaak moeilijk te gebruiken zonder domeinkennis van de specifieke bron en diens datamodel. (zie ook Linked Data).
Om die reden zetten we de data om naar één of meerdere views (datamodellen) wat dichter bij de wens van de gebruiker zitten. Dit is zichtbaar in de gele laag. (zie ook Knowledge Graph).
Uiteindelijk bieden we op basis van standaard services (bijv. REST / ElasticSearch / SPARQL / GraphQL) verschillende stopcontacten waar een gebruiker middels zijn applicatie op kan aansluiten. Hierbij interpreteren we een applicatie als een breed begrip. Zo is de metadata bijvoorbeeld ook gemakkelijk vindbaar voor een zoekmachine als Google. (zie ook Gebruik).
Kernprincipes
Om tot deze solution architecture te komen zijn een aantal kernprincipes van belang die relevant zijn geweest in de totstandkoming. Deze principes zijn:
- Data komt zo dicht mogelijk bij de bron weg. Enkel noodzakelijke kopieën worden gebruikt.
- Data lineage is van essentieel belang. Het moet bij alle data herkenbaar zijn waar deze zijn oorsprong vindt.
- De Data Governance is duidelijk. Ieder tussenproduct van de data heeft een duidelijke eigenaar.
- Tussenproducten in de architectuur dienen allemaal een doel. Data wordt niet onnodig ontsloten.
- Data is rijk aan metadata en semantiek. Dit is onderdeel van de data die wij ontsluiten.